


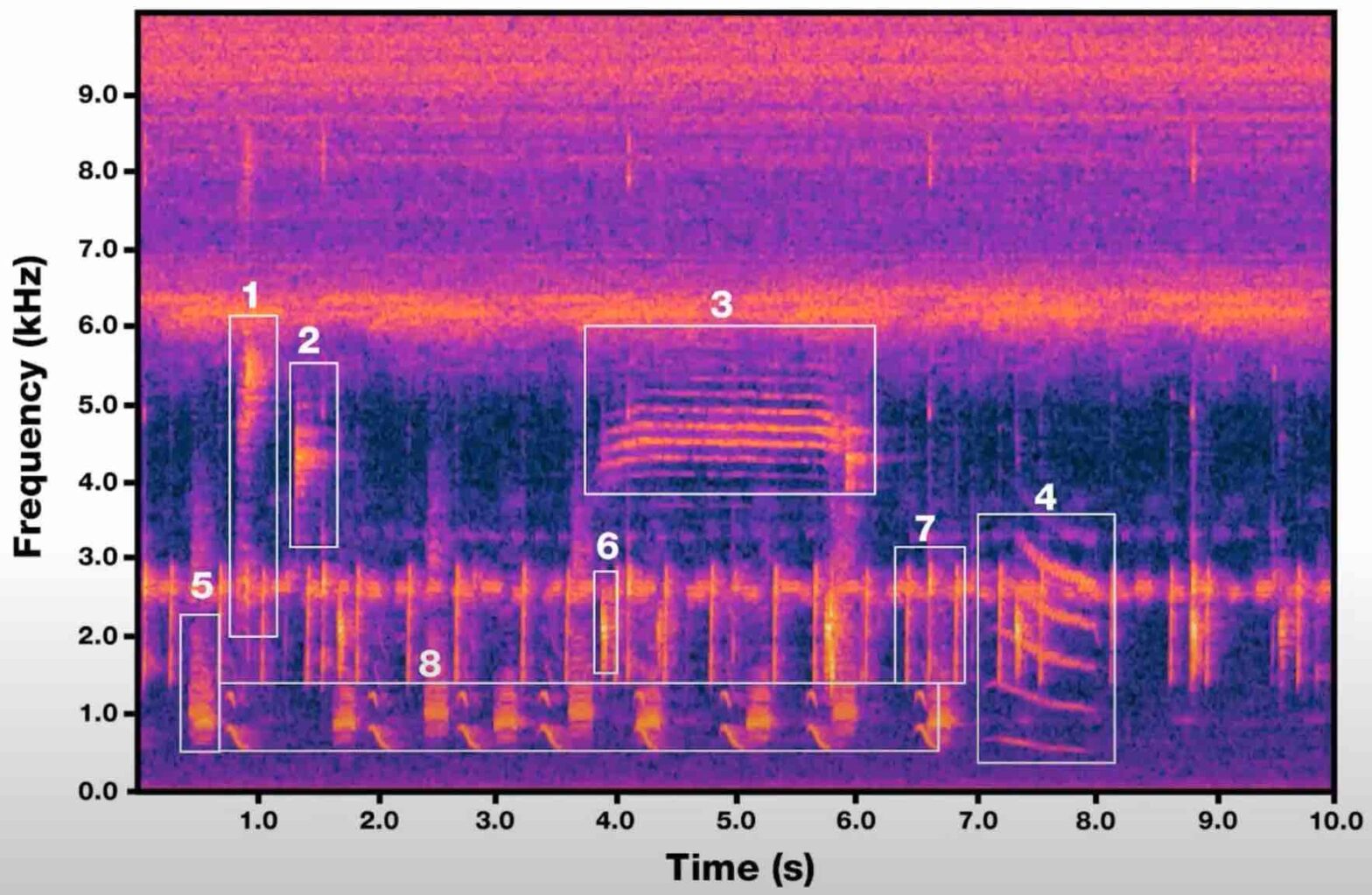
A demonstration by independent researcher Loïc Jankowiak, who visited LS2N in 2023 and 2024 as part of the ApEx project of Han Han. This is an in-progress build of a physically-modelled drum synthesizer using the Functional Transformation Method (FTM), with external MIDI control. The Embodme Erae Touch control surface is used for the velocity and… Continue reading Loïc demonstrates his FTM Synthesizer on Erae Touch
Author: Vincent Lostanlen
Mixture of Mixups for Multi-label Classification of Rare Anuran Sounds @ EUSIPCO
Multi-label imbalanced classification poses a significant challenge in machine learning, particularly evident in bioacoustics where animal sounds often co-occur, and certain sounds are much less frequent than others. This paper focuses on the specific case of classifying anuran species sounds using the dataset AnuraSet, that contains both class imbalance and multi-label examples. To address these challenges, we introduce Mixture of Mixups (Mix2), a framework that leverages mixing regularization methods Mixup, Manifold Mixup, and MultiMix. Experimental results show that these methods, individually, may lead to suboptimal results; however, when applied randomly, with one selected at each training iteration, they prove effective in addressing the mentioned challenges, particularly for rare classes with few occurrences. Further analysis reveals that the model trained using Mix2 is also proficient in classifying sounds across various levels of class co-occurrences.
Phantasmagoria: Sound Synthesis After the Turing Test @ S4

Sound synthesis with computers is often described as a Turing test or “imitation game”. In this context, a passing test is regarded by some as evidence of machine intelligence and by others as damage to human musicianship. Yet, both sides agree to judge synthesizers on a perceptual scale from fake to real. My article rejects this premise and borrows from philosopher Clément Rosset’s “L’Objet singulier” (1979) and “Fantasmagories” (2006) to affirm (1) the reality of all music, (2) the infidelity of all audio data, and (3) the impossibility of strictly repeating sensations. Compared to analog tape manipulation, deep generative models are neither more nor less unfaithful. In both cases, what is at stake is not to deny reality via illusion but to cultivate imagination as “function of the unreal” (Bachelard); i.e., a precise aesthetic grip on reality. Meanwhile, i insist that digital music machines are real objects within real human societies: their performance on imitation games should not exonerate us from studying their social and ecological impacts.
Machine listening symposium at World Ecoacoustics Congress

The 10th edition of the World Ecoacoustics Congress was held in Madrid between July 8th and July 12th. In this context, Juan Sebastián Ulloa and myslef have co-organized a special 3-hour symposium titled “Machine listening meets passive acoustic monitoring”. This event is supported by CAPTEO and PETREL projects.
WeAMEC PETREL project presented at Seanergy

Seanergy, the leading international event on offshore renewables energy, had its 2024 edition at Parc des expositions in Nantes. As part of the PETREL project, i have presented a poster with the title: “Towards the sustainable design of smart acoustic sensors for environmental monitoring of offshore renewables”. We reproduce the abstract below. Full program: https://seanergy-forum.com/research-posters/… Continue reading WeAMEC PETREL project presented at Seanergy
Learning to Solve Inverse Problems for Perceptual Sound Matching @ IEEE TASLP
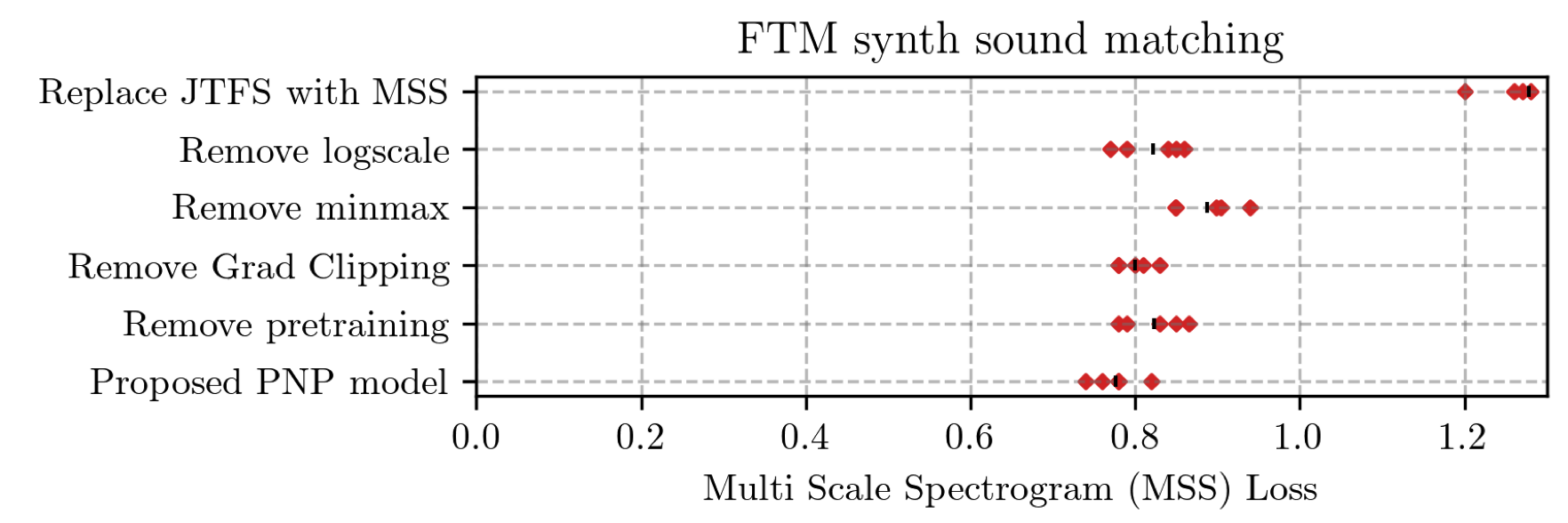
Perceptual sound matching (PSM) aims to find the input parameters to a synthesizer so as to best imitate an audio target. Deep learning for PSM optimizes a neural network to analyze and reconstruct prerecorded samples. In this context, our article addresses the problem of designing a suitable loss function when the training set is generated by a differentiable synthesizer. Our main contribution is perceptual–neural–physical loss (PNP), which aims at addressing a tradeoff between perceptual relevance and computational efficiency. The key idea behind PNP is to linearize the effect of synthesis parameters upon auditory features in the vicinity of each training sample. The linearization procedure is massively parallelizable, can be precomputed, and offers a 100-fold speedup during gradient descent compared to differentiable digital signal processing (DDSP). We show that PNP is able to accelerate DDSP with joint time–frequency scattering transform (JTFS) as auditory feature while preserving its perceptual fidelity. Additionally, we evaluate the impact of other design choices in PSM: parameter rescaling, pretraining, auditory representation, and gradient clipping. We report state-of-the-art results on both datasets and find that PNP-accelerated JTFS has greater influence on PSM performance than any other design choice.
Model-Based Deep Learning for Music Information Research @ IEEE SPM
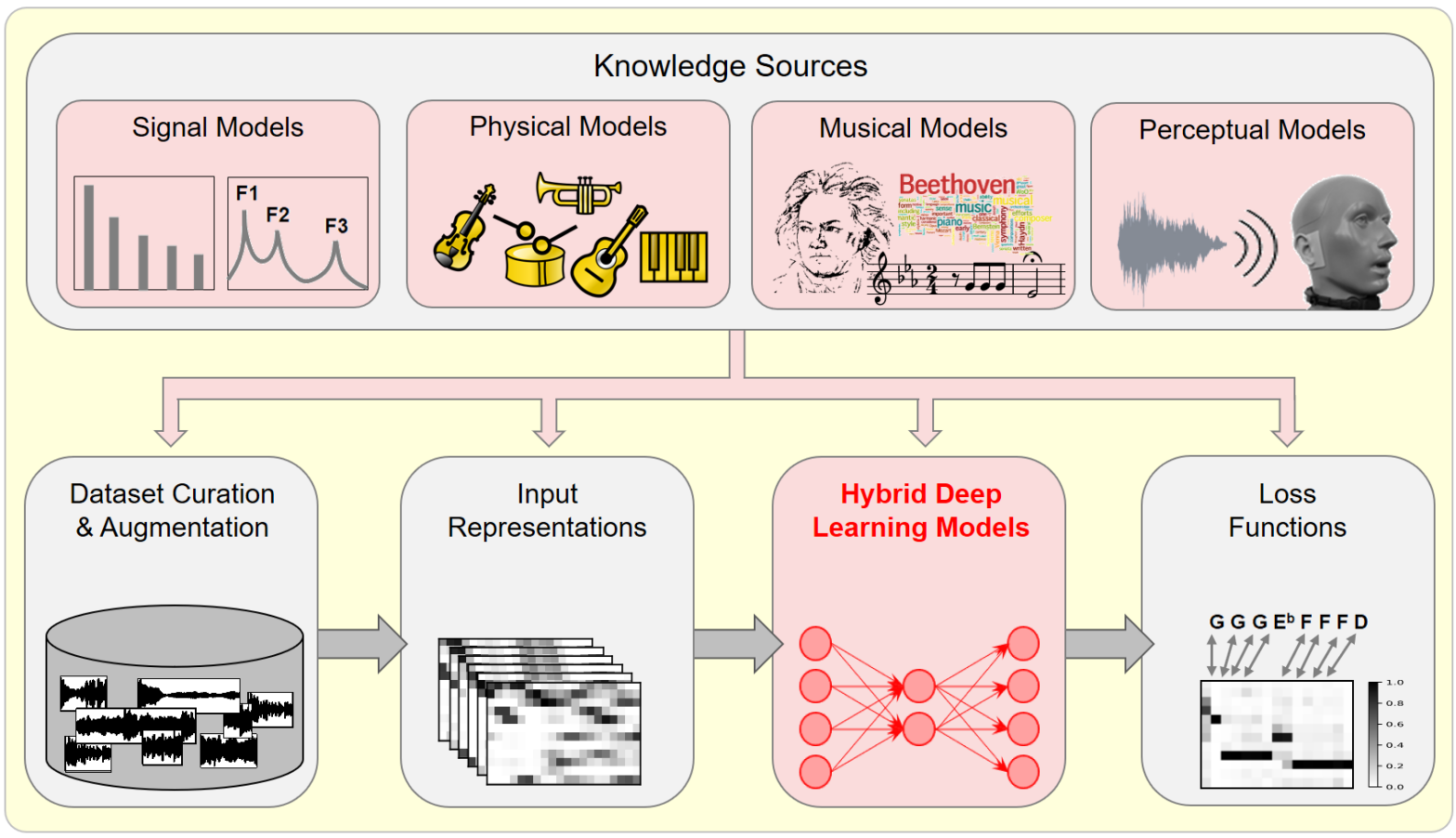
In this article, we investigate the notion of model-based deep learning in the realm of music information research (MIR). Loosely speaking, we refer to the term model-based deep learning for approaches that combine traditional knowledge-based methods with data-driven techniques, especially those based on deep learning, within a diff erentiable computing framework. In music, prior knowledge for instance related to sound production, music perception or music composition theory can be incorporated into the design of neural networks and associated loss functions. We outline three specific scenarios to illustrate the application of model-based deep learning in MIR, demonstrating the implementation of such concepts and their potential.
BioacAI doctoral network workshop in Czech Republic

From May 6th to May 10th, 2024, PhD student Yasmine Benhamadi and CNRS scientist Vincent Lostanlen have attended the first internal workshop of the BioacAI doctoral network. The Czech University of Life Sciences in Prague hosted the event in its University Forest Establishment, an ancient castle in the town of Kostelec nad Černými lesy. Yasmine… Continue reading BioacAI doctoral network workshop in Czech Republic
Action “Musiscale” au symposium du GDR MaDICS
Le 30 mai 2024 à Blois, se tenait le sixième symposium du GDR MaDICS : masses de données, informations et connaissances en sciences. Dans le cadre de l’action “Musiscale : modélisation multi-échelles de masses de données musicales”, j’ai présenté les travaux de l’équipe sur la diffusion en ondelettes (scattering transform) ainsi que sur les réseaux… Continue reading Action “Musiscale” au symposium du GDR MaDICS
Japanese–French Frontiers of Science Symposium 「日仏先端科学シンポジウム」

The 11th Japanese–French Frontiers of Science Symposium (JFFoS) 「日仏先端科学シンポジウム」was held at the University of Strasbourg from May 24th to 28th, as a joint event between the CNRS and the Japanese Society for the Promotion of Science (JSPS). Program: https://www.jsps.go.jp/english/e-fos/e-jffos/2024_11.html Vincent presented an overview of the research activities of the Audio @ LS2N, under the title… Continue reading Japanese–French Frontiers of Science Symposium 「日仏先端科学シンポジウム」