

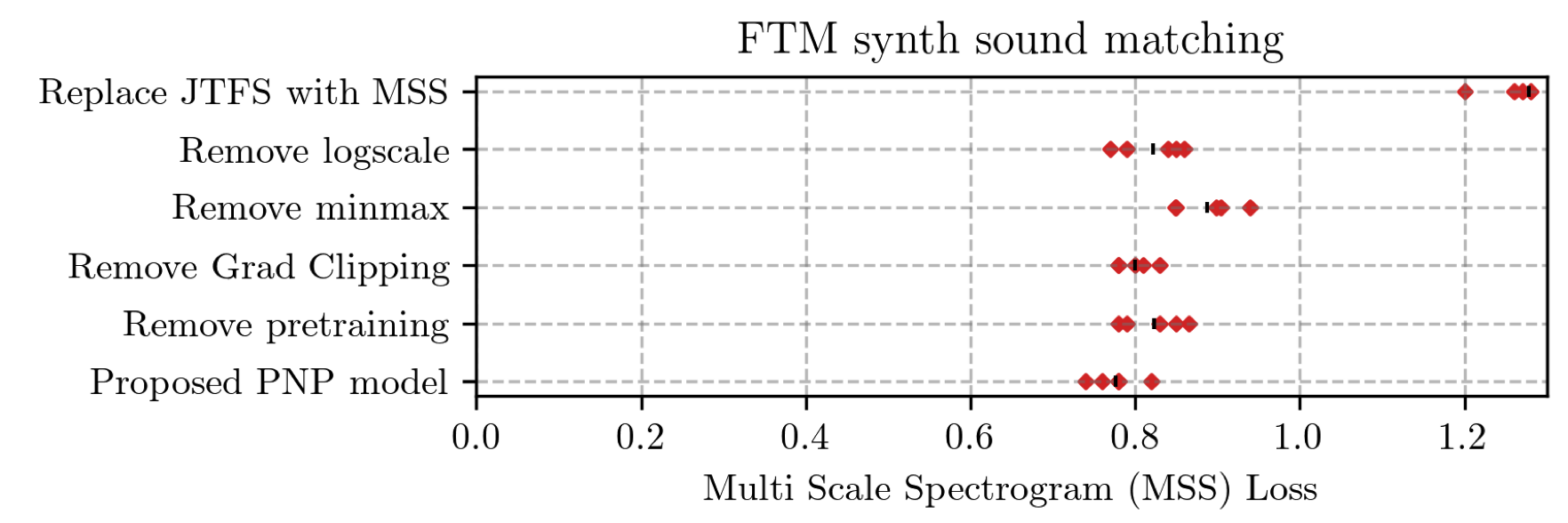
Perceptual sound matching (PSM) aims to find the input parameters to a synthesizer so as to best imitate an audio target. Deep learning for PSM optimizes a neural network to analyze and reconstruct prerecorded samples. In this context, our article addresses the problem of designing a suitable loss function when the training set is generated by a differentiable synthesizer. Our main contribution is perceptual–neural–physical loss (PNP), which aims at addressing a tradeoff between perceptual relevance and computational efficiency. The key idea behind PNP is to linearize the effect of synthesis parameters upon auditory features in the vicinity of each training sample. The linearization procedure is massively parallelizable, can be precomputed, and offers a 100-fold speedup during gradient descent compared to differentiable digital signal processing (DDSP). We show that PNP is able to accelerate DDSP with joint time–frequency scattering transform (JTFS) as auditory feature while preserving its perceptual fidelity. Additionally, we evaluate the impact of other design choices in PSM: parameter rescaling, pretraining, auditory representation, and gradient clipping. We report state-of-the-art results on both datasets and find that PNP-accelerated JTFS has greater influence on PSM performance than any other design choice.
Tag: kymatio
Kymatio notebooks @ ISMIR 2023

On November 5th, 2023, we hosted a tutorial on Kymatio, entitled “Deep Learning meets Wavelet Theory for Music Signal Processing”, as part of the International Society for Music Information Retrieval (ISMIR) conference in Milan, Italy. The Jupyter notebooks below were authored by Chris Mitcheltree and Cyrus Vahidi from Queen Mary University of London. I. Wavelets… Continue reading Kymatio notebooks @ ISMIR 2023
Mesostructures: Beyond spectrogram loss in differentiable time-frequency analysis @ JAES
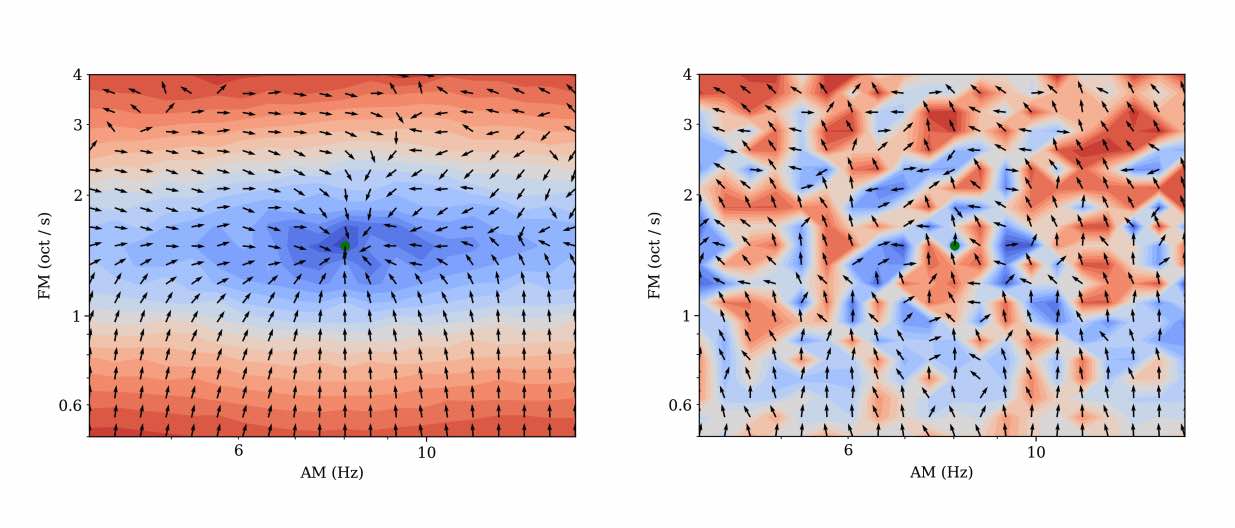
Computer musicians refer to mesostructures as the intermediate levels of articulation between the microstructure of waveshapes and the macrostructure of musical forms. Examples of mesostructures include melody, arpeggios, syncopation, polyphonic grouping, and textural contrast. Despite their central role in musical expression, they have received limited attention in recent applications of deep learning to the analysis and synthesis of musical audio. Currently, autoencoders and neural audio synthesizers are only trained and evaluated at the scale of microstructure: i.e., local amplitude variations up to 100 milliseconds or so. In this paper, we formulate and address the problem of mesostructural audio modeling via a composition of a differentiable arpeggiator and time-frequency scattering. We empirically demonstrate that time-frequency scattering serves as a differentiable model of similarity between synthesis parameters that govern mesostructure. By exposing the sensitivity of short-time spectral distances to time alignment, we motivate the need for a time-invariant and multiscale differentiable time-frequency model of similarity at the level of both local spectra and spectrotemporal modulations.
Explainable audio classification of playing techniques with layerwise relevance propagation @ IEEE ICASSP
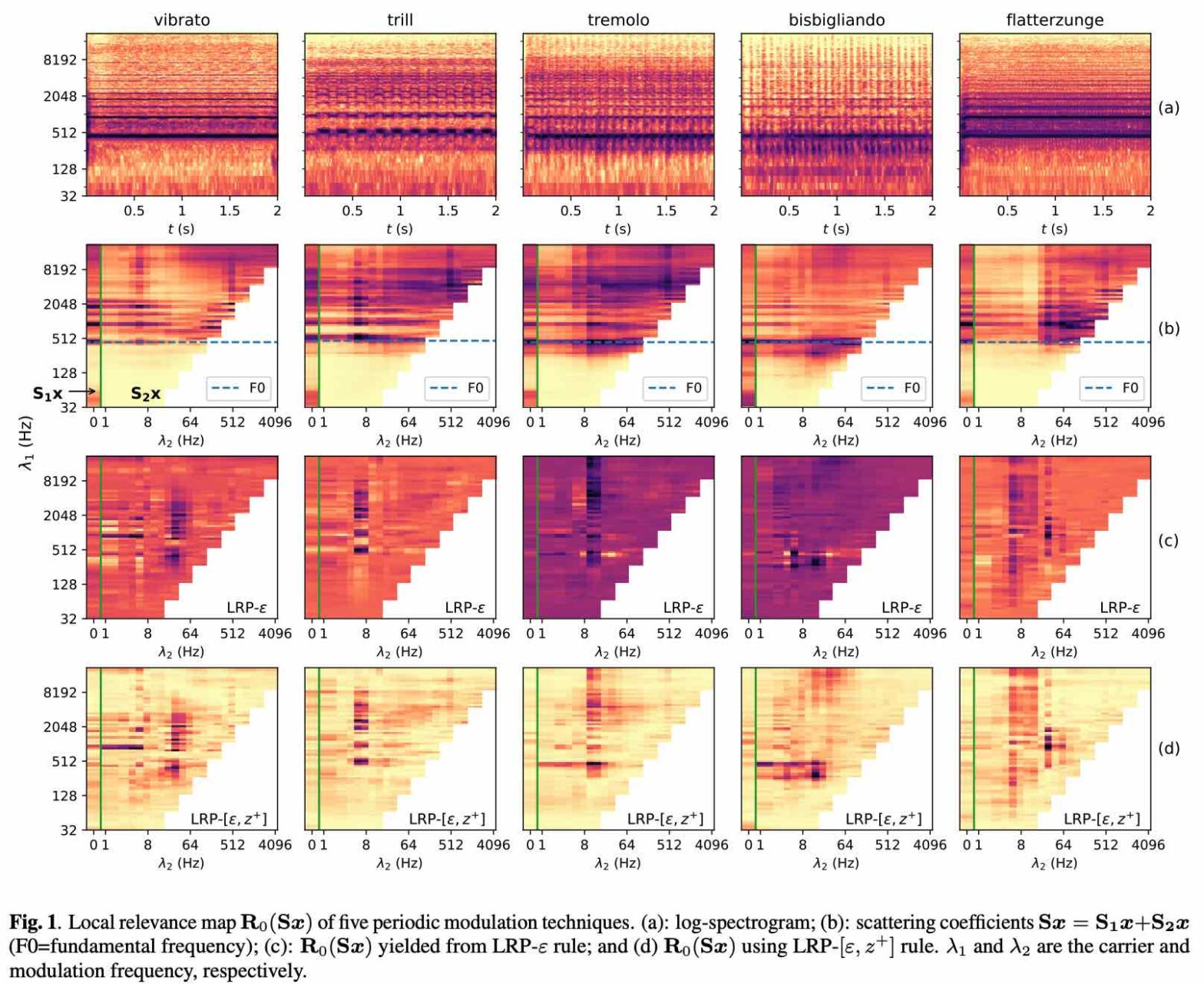
Deep convolutional networks (convnets) in the time-frequency domain can learn an accurate and fine-grained categorization of sounds. For example, in the context of music signal analysis, this categorization may correspond to a taxonomy of playing techniques: vibrato, tremolo, trill, and so forth. However, convnets lack an explicit connection with the neurophysiological underpinnings of musical timbre perception. In this article, we propose a data-driven approach to explain audio classification in terms of physical attributes in sound production. We borrow from current literature in “explainable AI” (XAI) to study the predictions of a convnet which achieves an almost perfect score on a challenging task: i.e., the classification of five comparable real-world playing techniques from 30 instruments spanning seven octaves. Mapping the signal into the carrier-modulation domain using scattering transform, we decompose the networks’ predictions over this domain with layer-wise relevance propagation. We find that regions highly-relevant to the predictions localized around the physical attributes with which the playing techniques are performed.
Announcing Kymatio tutorial @ ISMIR
We will present a tutorial on Kymatio at the International Society for Music Information Retrieval (ISMIR) Conference, held in Milan on November 5-9, 2023. Kymatio: Deep Learning meets Wavelet Theory for Music Signal Processing Kymatio is a Python package for applications at the intersection of deep learning and wavelet scattering. Its v0.4 release provides an… Continue reading Announcing Kymatio tutorial @ ISMIR
Perceptual–Physical–Sound Matching @ IEEE ICASSP
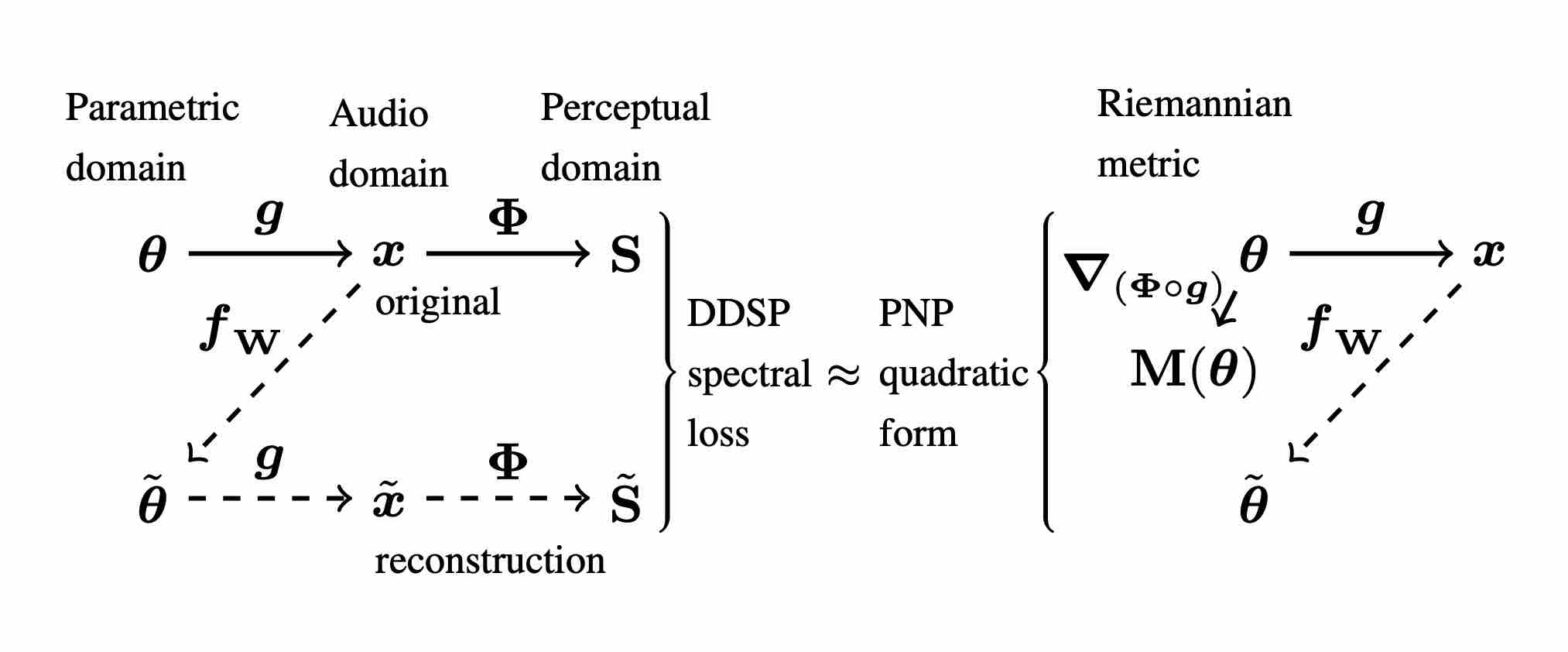
Sound matching algorithms seek to approximate a target waveform by parametric audio synthesis. Deep neural networks have achieved promising results in matching sustained harmonic tones. However, the task is more challenging when targets are nonstationary and inharmonic, e.g., percussion. We attribute this problem to the inadequacy of loss function. On one hand, mean square error in the parametric domain, known as “P-loss”, is simple and fast but fails to accommodate the differing perceptual significance of each parameter. On the other hand, mean square error in the spectrotemporal domain, known as “spectral loss”, is perceptually motivated and serves in differentiable digital signal processing (DDSP). Yet, spectral loss is a poor predictor of pitch intervals and its gradient may be computationally expensive; hence a slow convergence. Against this conundrum, we present Perceptual-Neural-Physical loss (PNP). PNP is the optimal quadratic approximation of spectral loss while being as fast as P-loss during training. We instantiate PNP with physical modeling synthesis as decoder and joint time-frequency scattering transform (JTFS) as spectral representation. We demonstrate its potential on matching synthetic drum sounds in comparison with other loss functions.