


STONE, the current method in self-supervised learning for tonality estimation in music signals, cannot distinguish relative keys, such as C major versus A minor. In this article, we extend the neural network architecture and learning objective of STONE to perform self-supervised learning of major and minor keys (S-KEY). Our main contribution is an auxiliary pretext task to STONE, formulated using transposition-invariant chroma features as a source of pseudo-labels. S-KEY matches the supervised state of the art in tonality estimation on FMAKv2 and GTZAN datasets while requiring no human annotation and having the same parameter budget as STONE. We build upon this result and expand the training set of S-KEY to a million songs, thus showing the potential of large-scale self-supervised learning in music information retrieval.
Tag: music
Création “in earth we walk” @ Halle 6

A live performance for voice, live electronics, and double bass. Created by Han Han
In earth we walk is a fleeting moment where voices become agents for constructing nature-inspired landscapes: voices utter semantically charged words conveying vivid scenarios; voices supply raw sonic material that are treated as pure sounds. The libretto is a six-stanza poem that unfolds a series of pictorial and psychological scenes, exploring themes of longing, awe and the reckoning with impermanence. Together, vocal emulations of clouds, torrent, winds, tides and sands weave into a sonic experience that evokes one’s multifaceted relationship with the many wonders and situations earth puts one in.
Podcast “Musique et IA” sur France musique

L’intelligence artificielle est partout, y compris dans le domaine musical. Qu’il s’agisse de “générer” des musiques à partir de données existantes, de créer une musique 100 % originale ou de réaliser certaines tâches pratiques, les usages sont nombreux et les inquiétudes aussi.
Model-based deep learning for music information research @ IEEE Signal Processing Magazine

We refer to the term model-based deep learning for approaches that combine traditional knowledge-based methods with data-driven techniques, especially those based on deep learning, within a differentiable computing framework. In music, prior knowledge for instance related to sound production, music perception or music composition theory can be incorporated into the design of neural networks and associated loss functions. We outline three specific scenarios to illustrate the application of model-based deep learning in MIR, demonstrating the implementation of such concepts and their potential.
Phantasmagoria @ Academy of Fine Arts of Munich

Invited talk: Yuexuan Kong

“STONE: Self-supervised tonality estimator”, at École Centrale de Nantes, amphi E, 2pm.
STONE: Self-supervised tonality estimator @ ISMIR
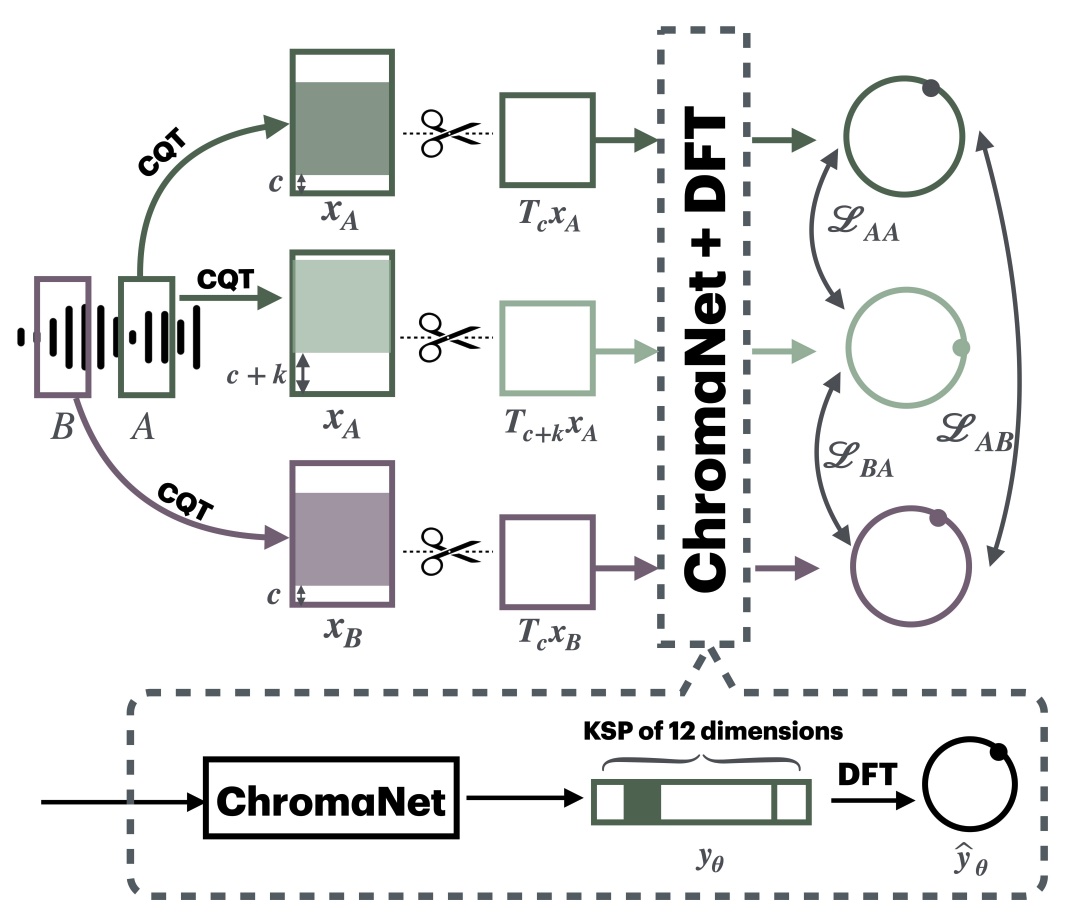
Although deep neural networks can estimate the key of a musical piece, their supervision incurs a massive annotation effort. Against this shortcoming, we present STONE, the first self-supervised tonality estimator. The architecture behind STONE, named ChromaNet, is a convnet with octave equivalence which outputs a “key signature profile” (KSP) of 12 structured logits. First, we train ChromaNet to regress artificial pitch transpositions between any two unlabeled musical excerpts from the same audio track, as measured as cross-power spectral density (CPSD) within the circle of fifths (CoF). We observe that this self-supervised pretext task leads KSP to correlate with tonal key signature. Based on this observation, we extend STONE to output a structured KSP of 24 logits, and introduce supervision so as to disambiguate major versus minor keys sharing the same key signature. Applying different amounts of supervision yields semi-supervised and fully supervised tonality estimators: i.e., Semi-TONEs and Sup-TONEs. We evaluate these estimators on FMAK, a new dataset of 5489 real-world musical recordings with expert annotation of 24 major and minor keys. We find that Semi-TONE matches the classification accuracy of Sup-TONE with reduced supervision and outperforms it with equal supervision.
EMVD dataset: a dataset of extreme vocal distortion techniques used in heavy metal @ CBMI
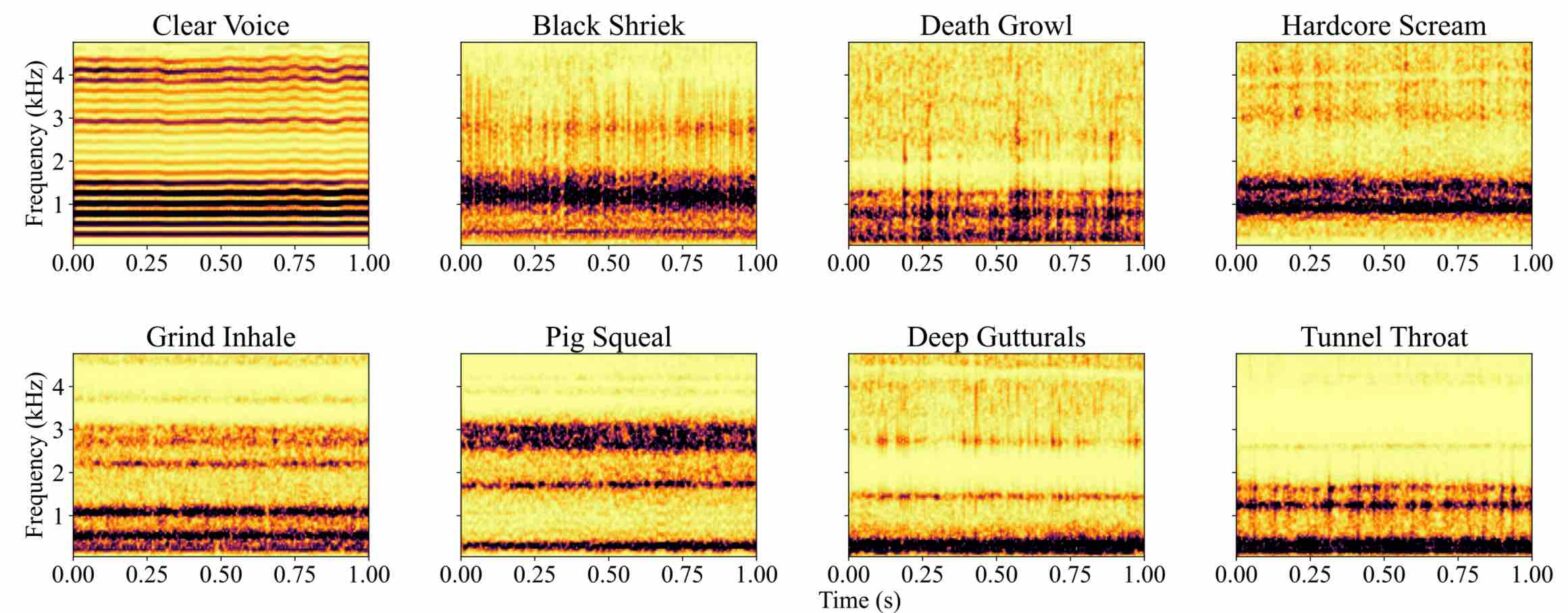
In this paper, we introduce the Extreme Metal Vocals Dataset, which comprises a collection of recordings of extreme vocal techniques performed within the realm of heavy metal music. The dataset consists of 760 audio excerpts of 1 second to 30 seconds long, totaling about 100 min of audio material, roughly composed of 60 minutes of distorted voices and 40 minutes of clear voice recordings. These vocal recordings are from 27 different singers and are provided without accompanying musical instruments or post-processing effects. The distortion taxonomy within this dataset encompasses four distinct distortion techniques and three vocal effects, all performed in different pitch ranges. Performance of a state-of-the-art deep learning model is evaluated for two different classification tasks related to vocal techniques, demonstrating the potential of this resource for the audio processing community.
On the Robustness of Musical Timbre Perception Models: From Perceptual to Learned Approaches @ EUSIPCO
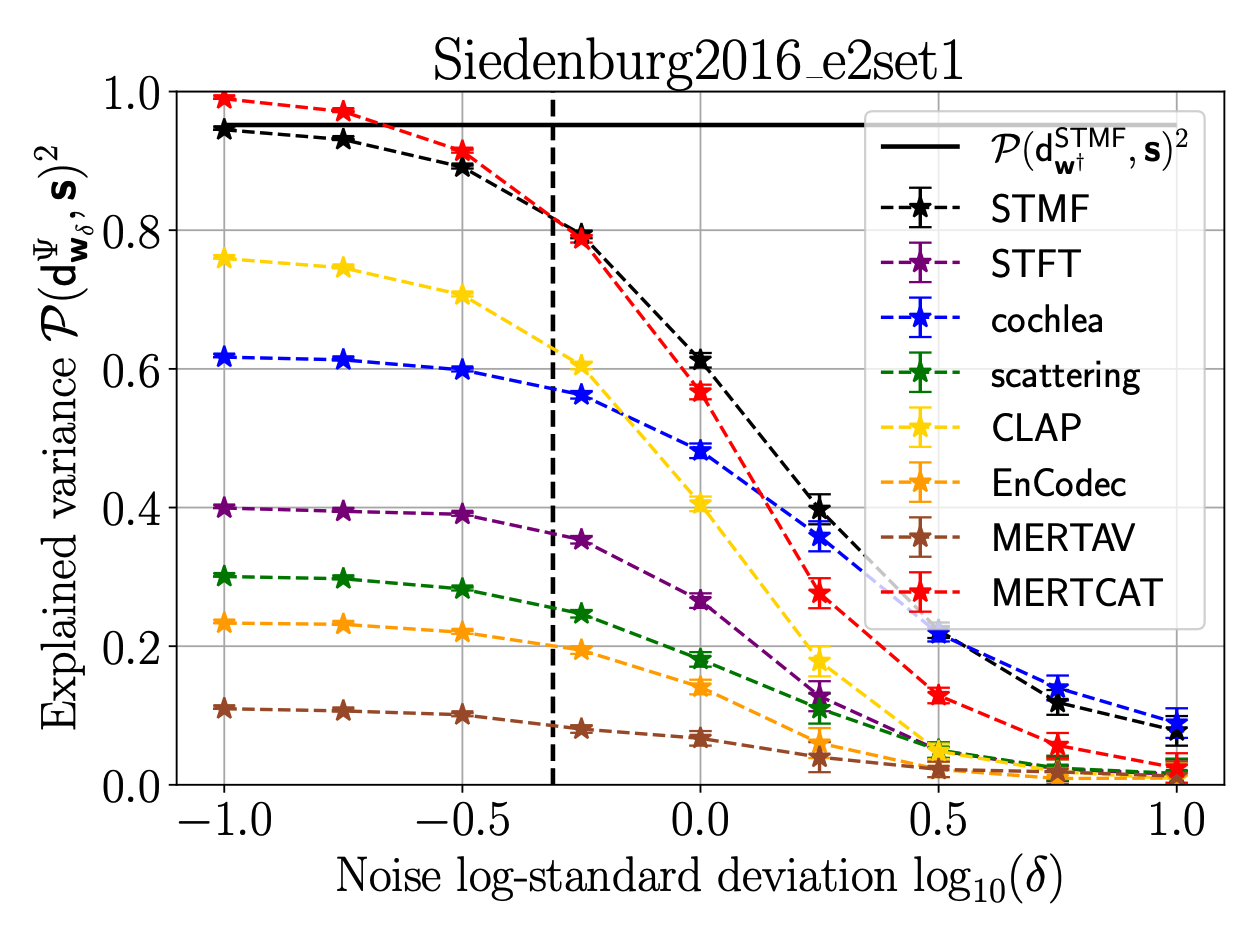
Timbre, encompassing an intricate set of acoustic cues, is key to identify sound sources, and especially to discriminate musical instruments and playing styles. Psychoacoustic studies focusing on timbre deploy massive efforts to explain human timbre perception. To uncover the acoustic substrates of timbre perceived dissimilarity, a recent work leveraged metric learning strategies on different perceptual representations and performed a meta-analysis of seventeen dissimilarity rated musical audio datasets. By learning salient patterns in very high-dimensional representations, metric learning accounts for a reasonably large part of the variance in human ratings. The present work shows that combining the most recent deep audio embeddings with a metric learning approach makes it possible to explain almost all the variance in human dissimilarity ratings. Furthermore, the robustness of the learning procedure against simulated human rating variability is thoroughly investigated. Intensive numerical experiments support the explanatory power and robustness against degraded dissimilarity ratings of the learning metric strategy using deep embeddings.
Content-Based Indexing for Audio and Music: From Analysis to Synthesis

Audio has long been a key component of multimedia research. As far as indexing is concerned, the research and industrial context has changed drastically in the last 20 years or so. Today, applications of audio indexing range from karaoke applications to singing voice synthesis and creative audio design. This special session aims at bringing together researchers that aim at proposing new tools or paradigms to investigate audio and music processing in the context of indexation and corpus-based generation.