


Welcome to our website. We are the special interest group on Audio at the Laboratoire des Sciences du Numérique de Nantes (France), or Audio@LS2N for short.
Bienvenue sur notre site. Nous sommes le groupe de travail sur l’audio du Laboratoire des sciences du numérique de Nantes (Audio@LS2N).


Loïc demonstrates his FTM Synthesizer on Erae Touch
A demonstration by independent researcher Loïc Jankowiak, who visited LS2N in 2023 and 2024 as…
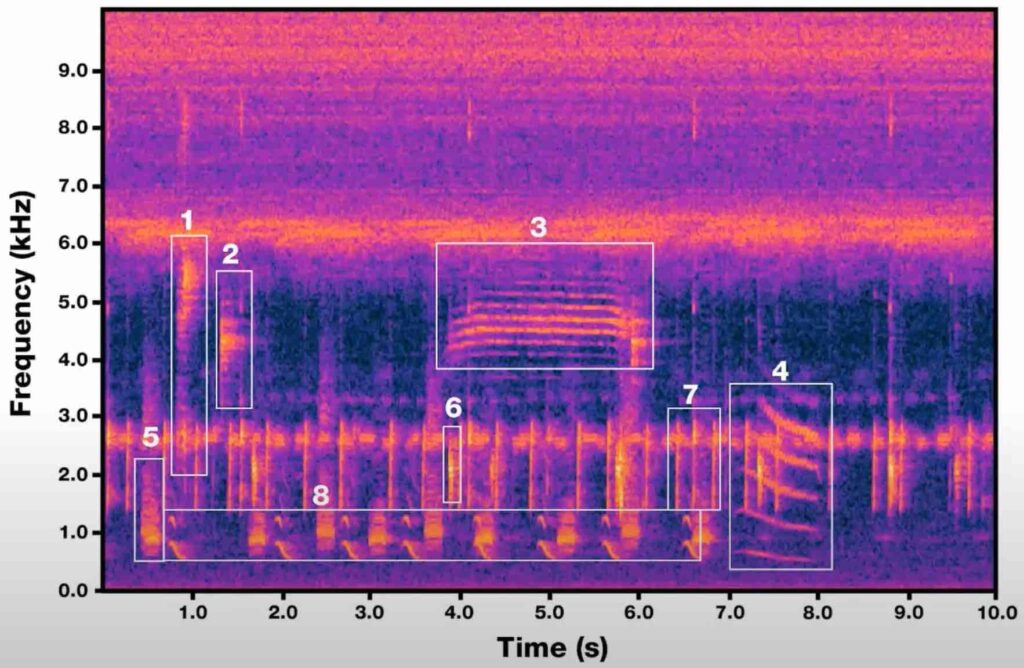
Mixture of Mixups for Multi-label Classification of Rare Anuran Sounds @ EUSIPCO
Multi-label imbalanced classification poses a significant challenge in machine learning, particularly evident in bioacoustics where…

Phantasmagoria: Sound Synthesis After the Turing Test @ S4
Sound synthesis with computers is often described as a Turing test or “imitation game”. In…

Machine listening symposium at World Ecoacoustics Congress
The 10th edition of the World Ecoacoustics Congress was held in Madrid between July 8th…

WeAMEC PETREL project presented at Seanergy
Seanergy, the leading international event on offshore renewables energy, had its 2024 edition at Parc…
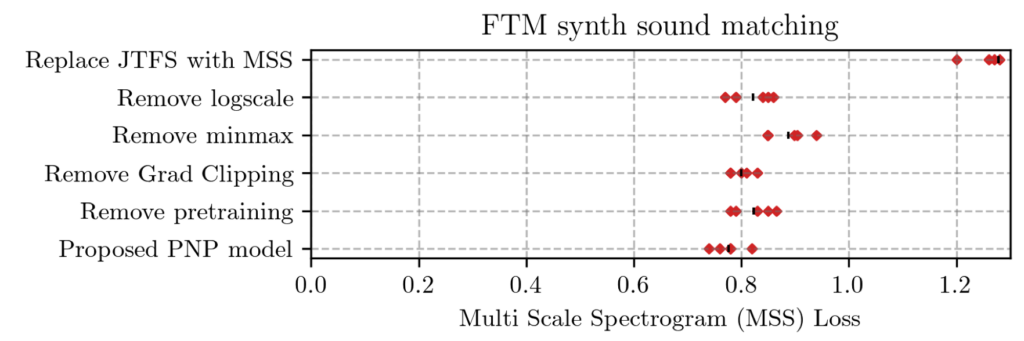
Learning to Solve Inverse Problems for Perceptual Sound Matching @ IEEE TASLP
Perceptual sound matching (PSM) aims to find the input parameters to a synthesizer so as…