

Le 30 mai 2024 à Blois, se tenait le sixième symposium du GDR MaDICS : masses de données, informations et connaissances en sciences. Dans le cadre de l’action “Musiscale : modélisation multi-échelles de masses de données musicales”, j’ai présenté les travaux de l’équipe sur la diffusion en ondelettes (scattering transform) ainsi que sur les réseaux… Continue reading Action “Musiscale” au symposium du GDR MaDICS
Tag: murenn-project
Structure Versus Randomness in Computer Music and the Scientific Legacy of Jean-Claude Risset @ JIM

According to Jean-Claude Risset (1938–2016), “art and science bring about complementary kinds of knowledge”. In 1969, he presented his piece Mutations as “[attempting] to explore […] some of the possibilities offered by the computer to compose at the very level of sound—to compose sound itself, so to speak.” In this article, I propose to take the same motto as a starting point, yet while adopting a mathematical and technological outlook, more so than a musicological one.
Instabilities in Convnets for Raw Audio @ IEEE SPL
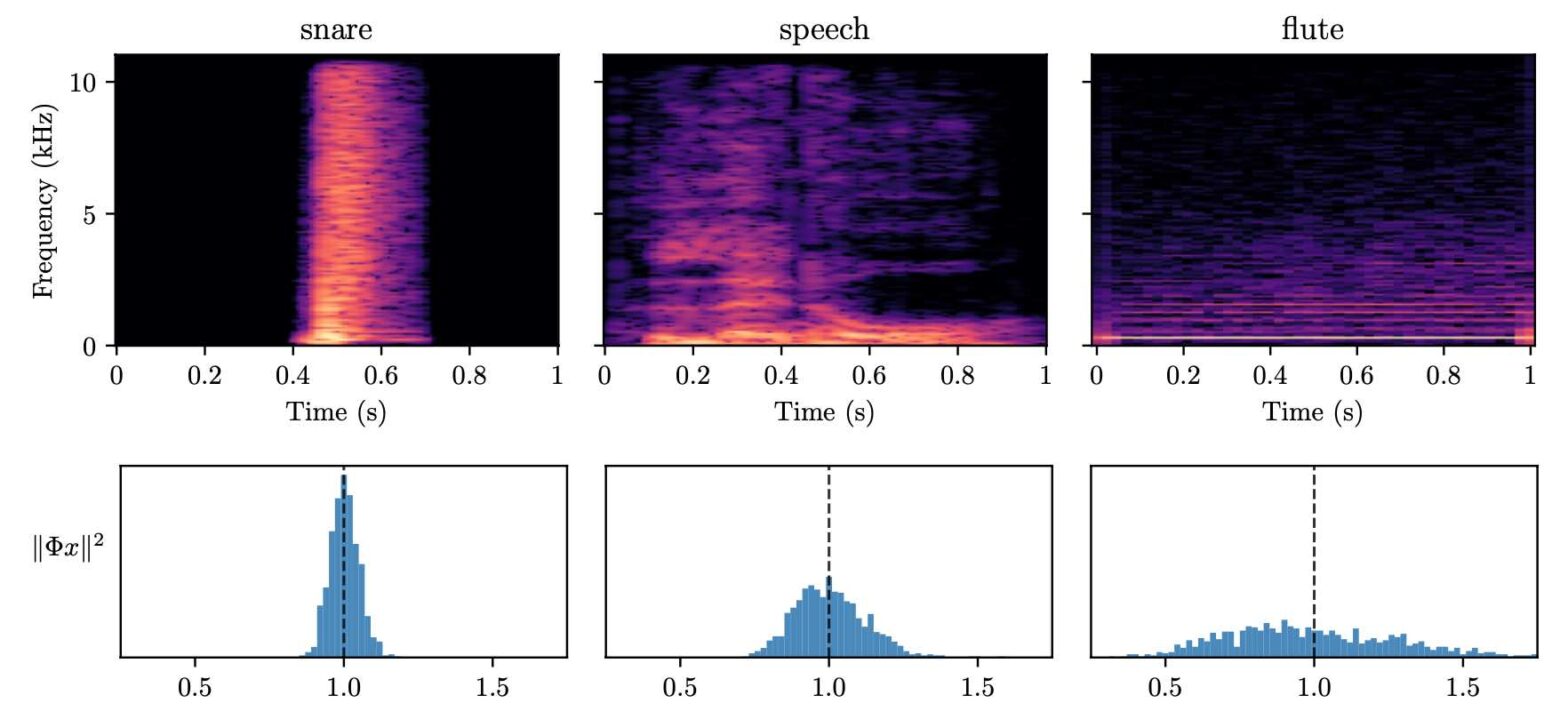
What makes waveform-based deep learning so hard? Despite numerous attempts at training convolutional neural networks (convnets) for filterbank design, they often fail to outperform hand-crafted baselines. These baselines are linear time-invariant systems: as such, they can be approximated by convnets with wide receptive fields. Yet, in practice, gradient-based optimization leads to suboptimal approximations. In our… Continue reading Instabilities in Convnets for Raw Audio @ IEEE SPL
Fitting Auditory Filterbanks with MuReNN @ IEEE WASPAA
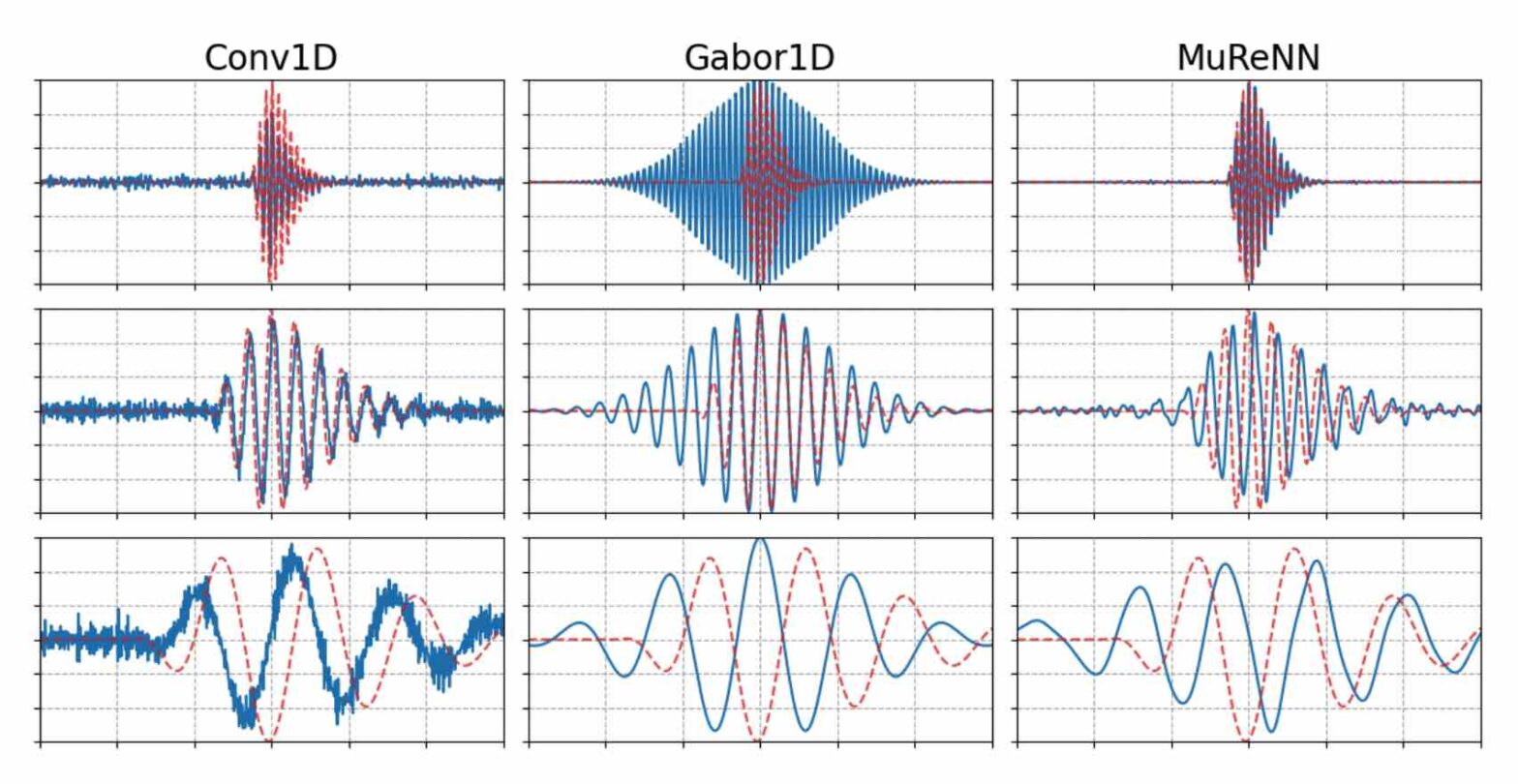
Waveform-based deep learning faces a dilemma between nonparametric and parametric approaches. On one hand, convolutional neural networks (convnets) may approximate any linear time-invariant system; yet, in practice, their frequency responses become more irregular as their receptive fields grow. On the other hand, a parametric model such as LEAF is guaranteed to yield Gabor filters, hence an optimal time-frequency localization; yet, this strong inductive bias comes at the detriment of representational capacity. In this paper, we aim to overcome this dilemma by introducing a neural audio model, named multiresolution neural network (MuReNN). The key idea behind MuReNN is to train separate convolutional operators over the octave subbands of a discrete wavelet transform (DWT). Since the scale of DWT atoms grows exponentially between octaves, the receptive fields of the subsequent learnable convolutions in MuReNN are dilated accordingly. For a given real-world dataset, we fit the magnitude response of MuReNN to that of a wellestablished auditory filterbank: Gammatone for speech, CQT for music, and third-octave for urban sounds, respectively. This is a form of knowledge distillation (KD), in which the filterbank “teacher” is engineered by domain knowledge while the neural network “student” is optimized from data. We compare MuReNN to the state of the art in terms of goodness of fit after KD on a hold-out set and in terms of Heisenberg time-frequency localization. Compared to convnets and Gabor convolutions, we find that MuReNN reaches state-of-the-art performance on all three optimization problems.
PhD offer: “Theory and implementation of multi-resolution neural networks”
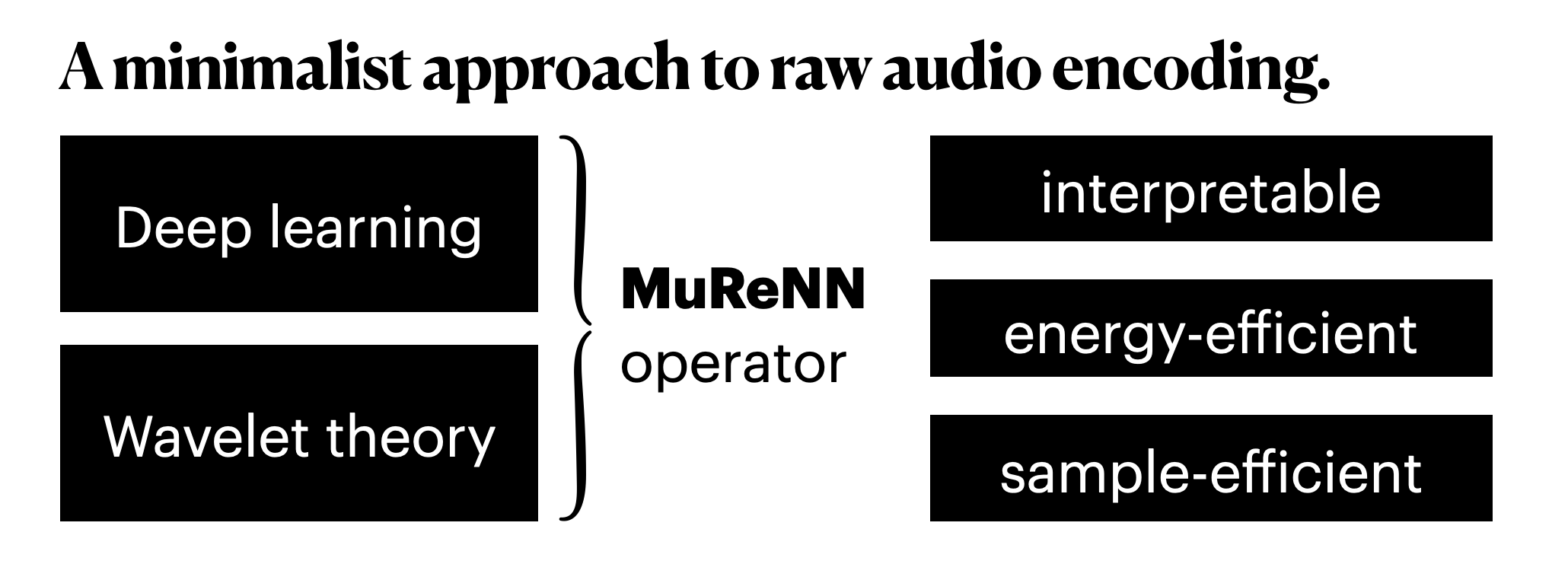
The French national center for scientific research (CNRS) is hiring a PhD student as part of a three-year project on “Multi-Resolution Neural Networks” (MuReNN). MuReNN is supported by the French national funding agency (ANR), and hosted at the Laboratoire des Sciences du Numérique de Nantes (LS2N). A collaboration with the Austrian Academy of Sciences is… Continue reading PhD offer: “Theory and implementation of multi-resolution neural networks”
MuReNN: Multi-Resolution Neural Networks
“Less is more”, once the foundational motto of minimalist art, is making its way into artificial intelligence. After a maximalist decade of larger computers training larger neural networks on larger datasets (2012-2022), a countertrend arises. What if human-level performance could be achieved with less computing, less memory, and less supervision? In deep learning, the research… Continue reading MuReNN: Multi-Resolution Neural Networks