

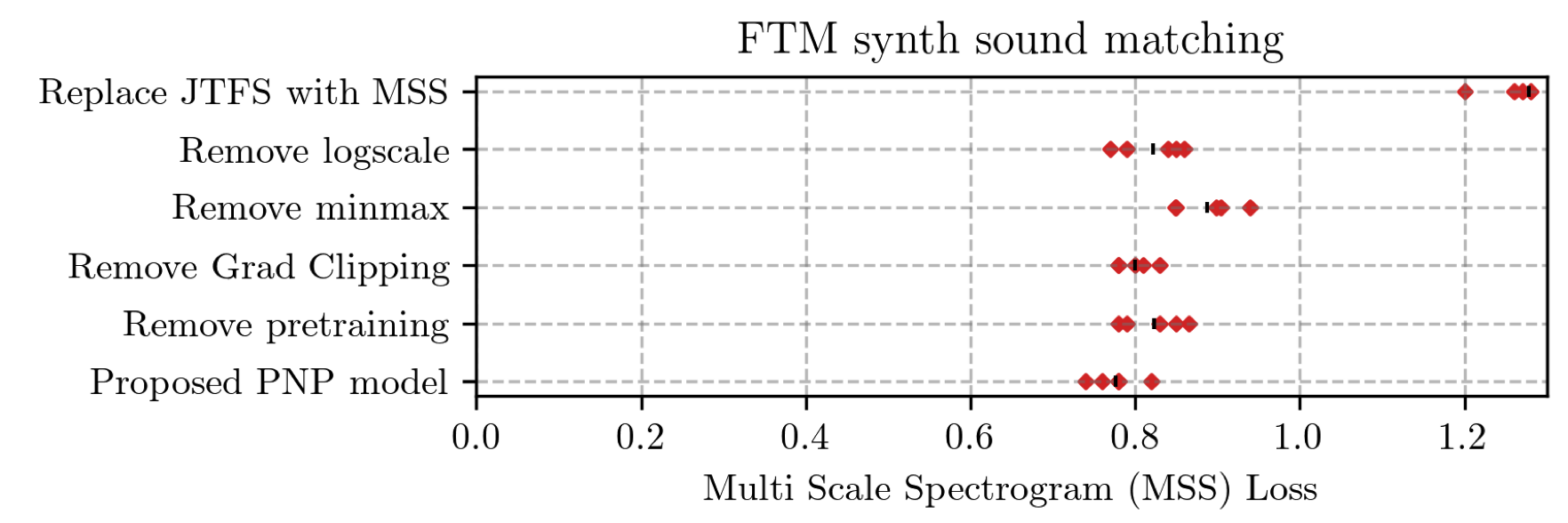
Perceptual sound matching (PSM) aims to find the input parameters to a synthesizer so as to best imitate an audio target. Deep learning for PSM optimizes a neural network to analyze and reconstruct prerecorded samples. In this context, our article addresses the problem of designing a suitable loss function when the training set is generated by a differentiable synthesizer. Our main contribution is perceptual–neural–physical loss (PNP), which aims at addressing a tradeoff between perceptual relevance and computational efficiency. The key idea behind PNP is to linearize the effect of synthesis parameters upon auditory features in the vicinity of each training sample. The linearization procedure is massively parallelizable, can be precomputed, and offers a 100-fold speedup during gradient descent compared to differentiable digital signal processing (DDSP). We show that PNP is able to accelerate DDSP with joint time–frequency scattering transform (JTFS) as auditory feature while preserving its perceptual fidelity. Additionally, we evaluate the impact of other design choices in PSM: parameter rescaling, pretraining, auditory representation, and gradient clipping. We report state-of-the-art results on both datasets and find that PNP-accelerated JTFS has greater influence on PSM performance than any other design choice.
Author: Han Han
Towards multisensory control of physical modeling synthesis @ Inter-Noise

Physical models of musical instruments offer an interesting tradeoff between computational efficiency and perceptual fidelity. Yet, they depend on a multidimensional space of user-defined parameters whose exploration by trial and error is impractical. Our article addresses this issue by combining two ideas: query by example and gestural control. On one hand, we train a deep… Continue reading Towards multisensory control of physical modeling synthesis @ Inter-Noise
Towards constructing a historically grounded gesture-timbre space of Guqin playing techniques @ Timbre

Guqin is an ancient Chinese zither instrument known for its timbral variability and the vital role timbre, as opposed to melody or rhythm, played in its classical compositions. Numerous ancient texts dating back to the 1500s provided gestural guidelines of defined Guqin playing techniques and recommendations on timbre aesthetics. It’s also suggested in these texts that small deviations in gestures have significant impact on resulting timbres. Nevertheless, traditionally and even today, Guqin pedagogies are largely metaphoric, mind instead of body, and include limited elaboration on recommended gestures. To digitize and concretize the sonic implications in Guqin gesture-timbre writings, and variegate within the oversimplified vocabulary of playing techniques, this study aims to design and record a dataset of isolated, short, representative Guqin sounds labeled by gestural data. The sounds in question are curated by extracting ancient text, where emphasis on gesture-induced timbral difference is mentioned. We decompose the notion of gesture into nine degrees of freedom for both hands, including left/right hand position, fingers used, point of contact, left/right hand temporal coordination, etc. We define a ladder of gestural data at various levels, ranging from discrete labels of playing techniques, the aforementioned degrees of freedom to continuous signals acquired by high-speed camera with automatic hand-tracking system. We analyze in time-frequency domain timbres resulting from conventional playing gestures and their systematically “perturbed” versions. We investigate the correlation between timbres and their underlying gestures, via methods derived from multidimensional scaling.
Le guqin : vers une cartographie gestuelle et timbrale

Le 1er décembre 2023 à 14h45, Han Han présentera son projet sur la cartographie gestuelle et timbrale du guqin (cithare chinoise) à la bibliothèque La Grange Fleuret, au 11 bis rue de Vézelay à Paris. Ce projet s’inscrit dans les “collaborations entre jeunes chercheuses et artistes” et est soutenu par l’association française d’informatique musicale (AFIM)… Continue reading Le guqin : vers une cartographie gestuelle et timbrale
Apprentissage de variété riemannienne pour l’analyse-synthèse de signaux non stationnaires @ GRETSI
Mesostructures: Beyond spectrogram loss in differentiable time-frequency analysis @ JAES
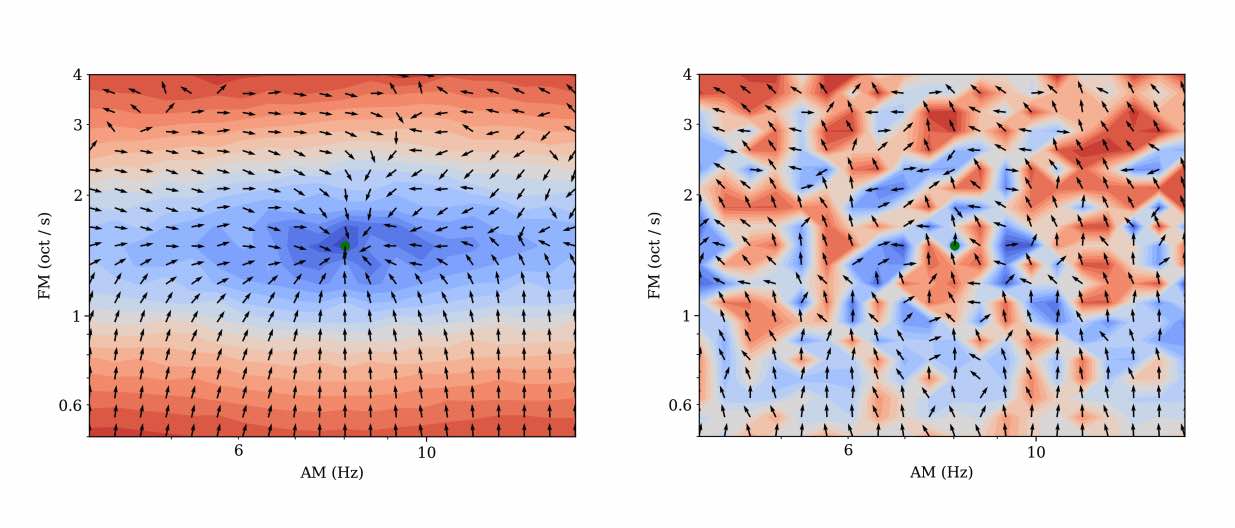
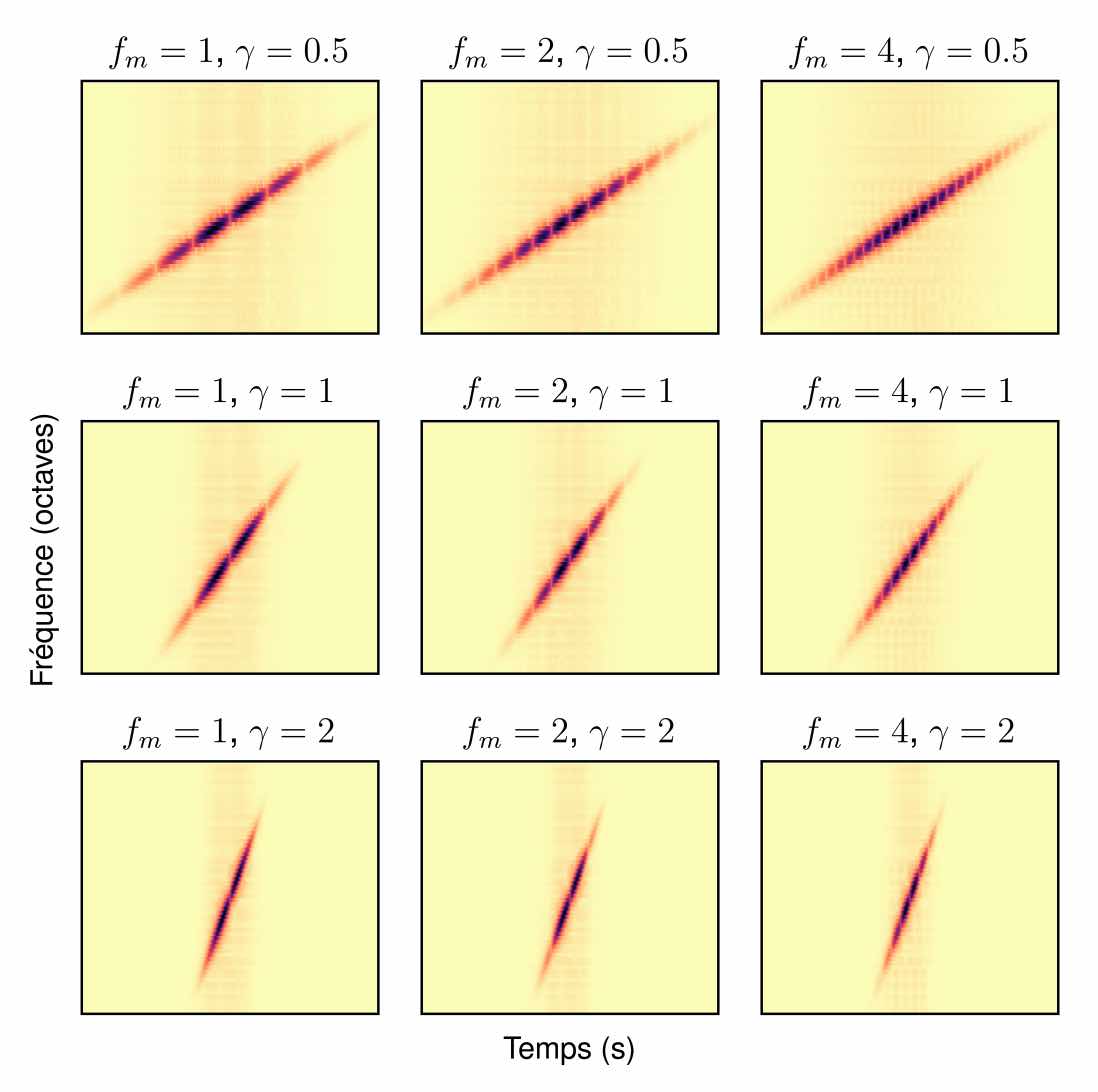
Computer musicians refer to mesostructures as the intermediate levels of articulation between the microstructure of waveshapes and the macrostructure of musical forms. Examples of mesostructures include melody, arpeggios, syncopation, polyphonic grouping, and textural contrast. Despite their central role in musical expression, they have received limited attention in recent applications of deep learning to the analysis and synthesis of musical audio. Currently, autoencoders and neural audio synthesizers are only trained and evaluated at the scale of microstructure: i.e., local amplitude variations up to 100 milliseconds or so. In this paper, we formulate and address the problem of mesostructural audio modeling via a composition of a differentiable arpeggiator and time-frequency scattering. We empirically demonstrate that time-frequency scattering serves as a differentiable model of similarity between synthesis parameters that govern mesostructure. By exposing the sensitivity of short-time spectral distances to time alignment, we motivate the need for a time-invariant and multiscale differentiable time-frequency model of similarity at the level of both local spectra and spectrotemporal modulations.
Fitting Auditory Filterbanks with MuReNN @ IEEE WASPAA
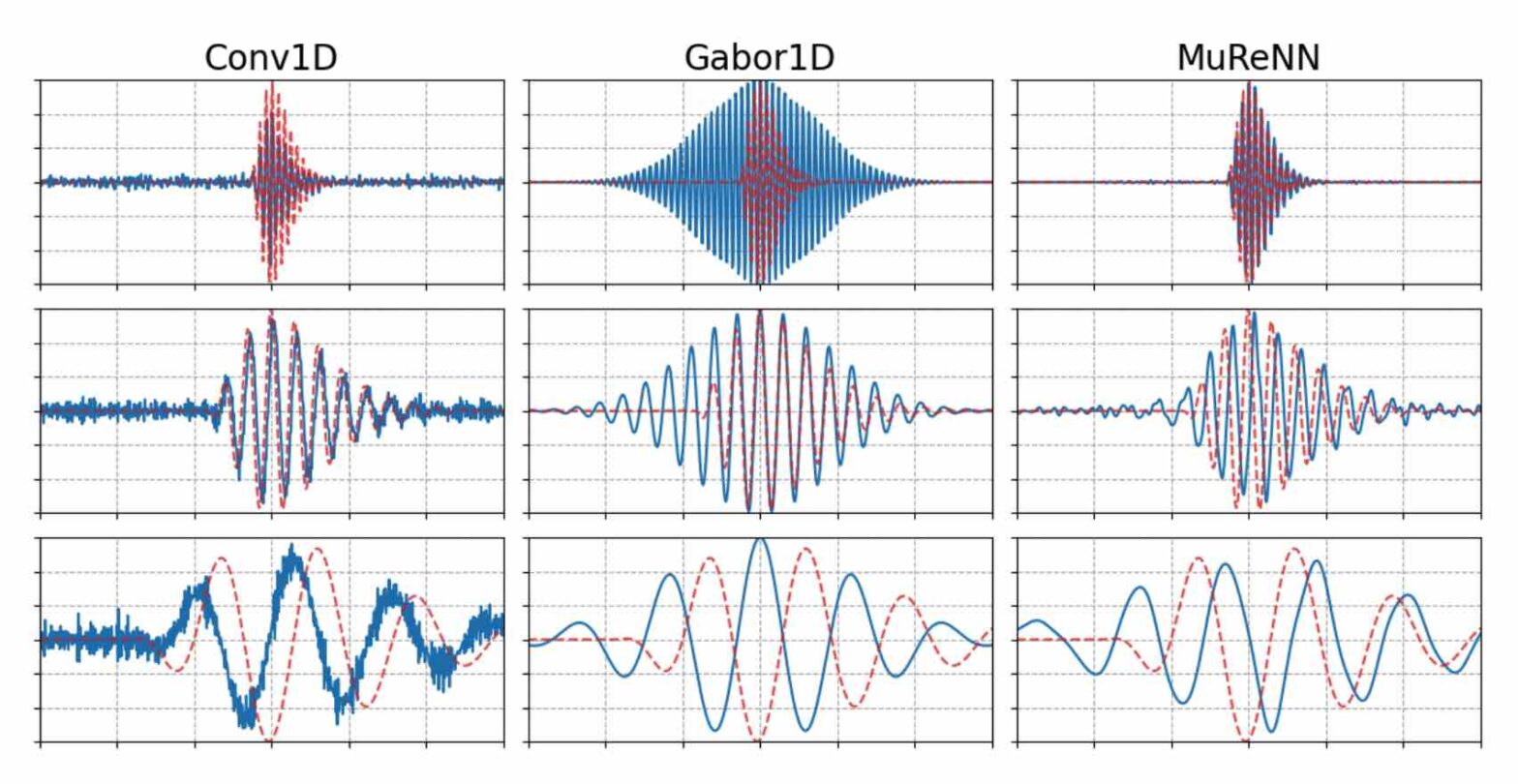
Waveform-based deep learning faces a dilemma between nonparametric and parametric approaches. On one hand, convolutional neural networks (convnets) may approximate any linear time-invariant system; yet, in practice, their frequency responses become more irregular as their receptive fields grow. On the other hand, a parametric model such as LEAF is guaranteed to yield Gabor filters, hence an optimal time-frequency localization; yet, this strong inductive bias comes at the detriment of representational capacity. In this paper, we aim to overcome this dilemma by introducing a neural audio model, named multiresolution neural network (MuReNN). The key idea behind MuReNN is to train separate convolutional operators over the octave subbands of a discrete wavelet transform (DWT). Since the scale of DWT atoms grows exponentially between octaves, the receptive fields of the subsequent learnable convolutions in MuReNN are dilated accordingly. For a given real-world dataset, we fit the magnitude response of MuReNN to that of a wellestablished auditory filterbank: Gammatone for speech, CQT for music, and third-octave for urban sounds, respectively. This is a form of knowledge distillation (KD), in which the filterbank “teacher” is engineered by domain knowledge while the neural network “student” is optimized from data. We compare MuReNN to the state of the art in terms of goodness of fit after KD on a hold-out set and in terms of Heisenberg time-frequency localization. Compared to convnets and Gabor convolutions, we find that MuReNN reaches state-of-the-art performance on all three optimization problems.
Perceptual–Physical–Sound Matching @ IEEE ICASSP
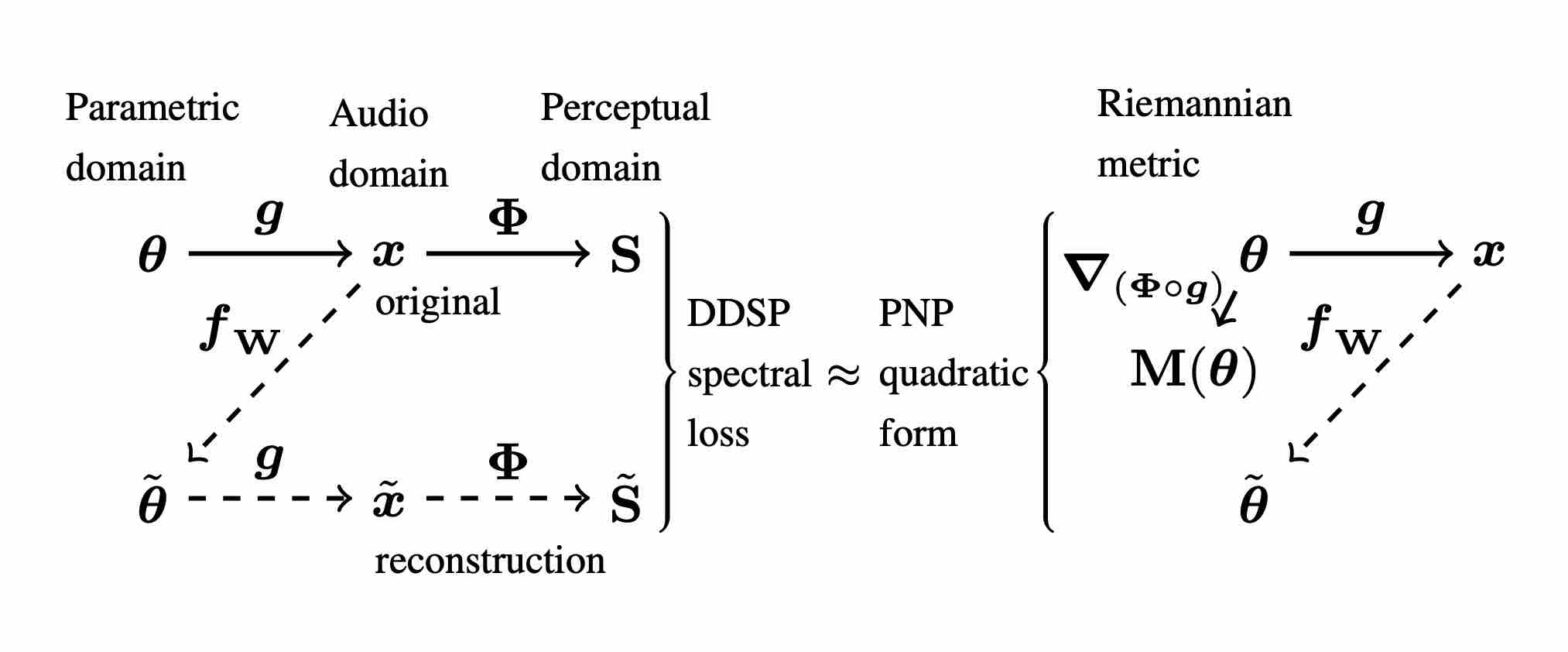
Sound matching algorithms seek to approximate a target waveform by parametric audio synthesis. Deep neural networks have achieved promising results in matching sustained harmonic tones. However, the task is more challenging when targets are nonstationary and inharmonic, e.g., percussion. We attribute this problem to the inadequacy of loss function. On one hand, mean square error in the parametric domain, known as “P-loss”, is simple and fast but fails to accommodate the differing perceptual significance of each parameter. On the other hand, mean square error in the spectrotemporal domain, known as “spectral loss”, is perceptually motivated and serves in differentiable digital signal processing (DDSP). Yet, spectral loss is a poor predictor of pitch intervals and its gradient may be computationally expensive; hence a slow convergence. Against this conundrum, we present Perceptual-Neural-Physical loss (PNP). PNP is the optimal quadratic approximation of spectral loss while being as fast as P-loss during training. We instantiate PNP with physical modeling synthesis as decoder and joint time-frequency scattering transform (JTFS) as spectral representation. We demonstrate its potential on matching synthetic drum sounds in comparison with other loss functions.