

A talk by Vincent Lostanlen at the Acoustics Research Institute (ARI) of the Austrian Academy of Sciences (ÖAW) in Vienna.
Tag: time-frequency
Sound source classification for soundscape analysis using fast third-octave bands data from an urban acoustic sensor network @ JASA
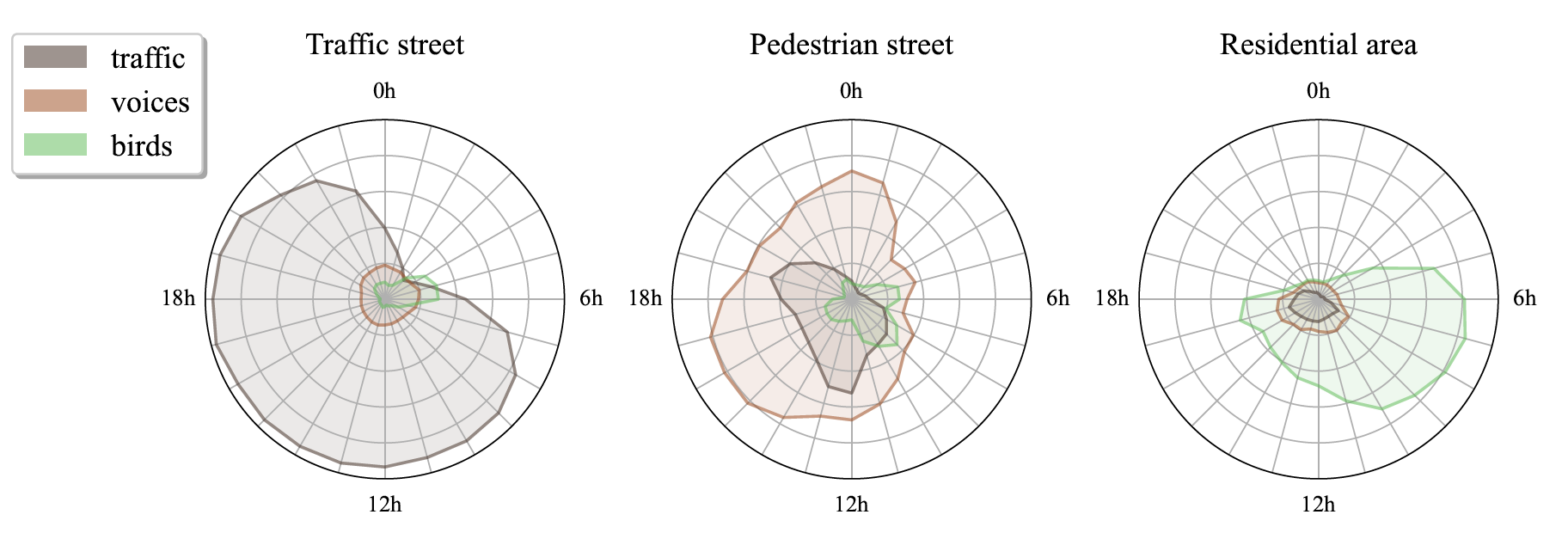
The exploration of the soundscape relies strongly on the characterization of the sound sources in the sound environment. Novel sound source classifiers, called pre-trained audio neural networks (PANNs), are capable of predicting the presence of more than 500 diverse sound sources. Nevertheless, PANNs models use fine Mel spectro-temporal representations as input, whereas sensors of an urban noise monitoring network often record fast third-octaves data, which have significantly lower spectro-temporal resolution. In a previous study, we developed a transcoder to transform fast third-octaves into the fine Mel spectro-temporal representation used as input of PANNs. In this paper, we demonstrate that employing PANNs with fast third-octaves data, processed through this transcoder, does not strongly degrade the classifier’s performance in predicting the perceived time of presence of sound sources. Through a qualitative analysis of a large-scale fast third-octave dataset, we also illustrate the potential of this tool in opening new perspectives and applications for monitoring the soundscapes of cities.
Correlation of Fréchet Audio Distance With Human Perception of Environmental Audio Is Embedding Dependent @ EUSIPCO
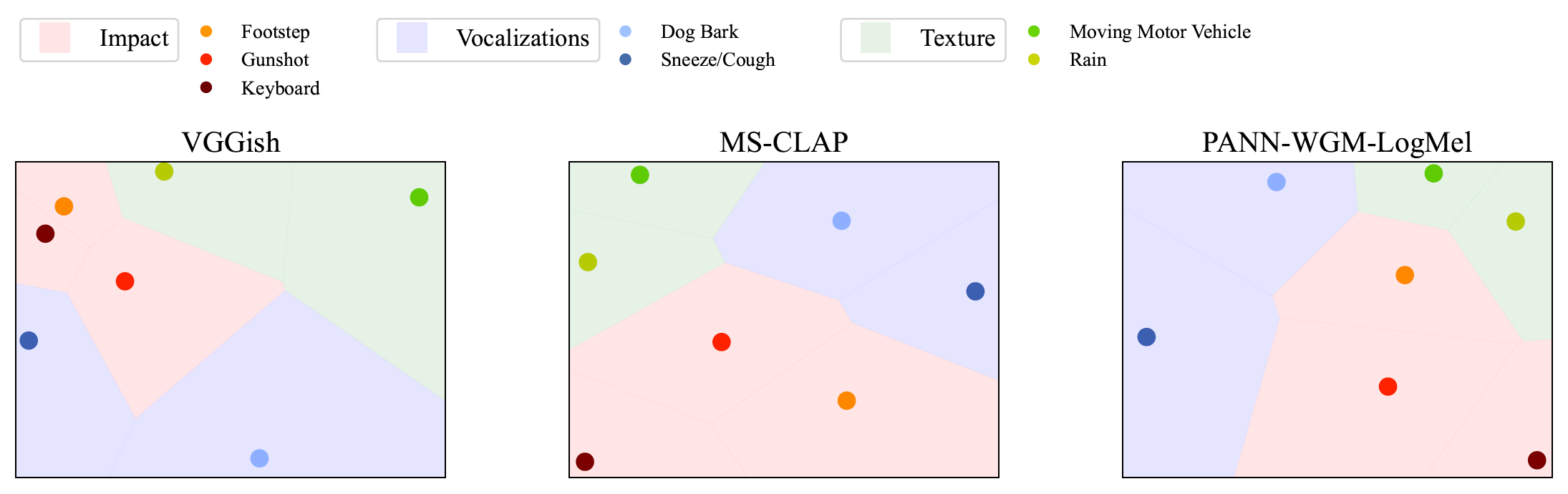
This paper explores whether considering alternative domain-specific embeddings to calculate the Frechet Audio Dis- tance (FAD) metric can help the FAD to correlate better with perceptual ratings of environmental sounds. We used embeddings from VGGish, PANNs, MS-CLAP, L-CLAP, and MERT, which are tailored for either music or environmental sound evaluation. The FAD scores were calculated for sounds from the DCASE 2023 Task 7 dataset. Using perceptual data from the same task, we find that PANNs-WGM-LogMel produces the best correlation between FAD scores and perceptual ratings of both audio quality and perceived fit with a Spearman correlation higher than 0.5. We also find that music-specific embeddings resulted in significantly lower results. Interestingly, VGGish, the embedding used for the original Frechet calculation, yielded a correlation below 0.1. These results underscore the critical importance of the choice of embedding for the FAD metric design.
On the Robustness of Musical Timbre Perception Models: From Perceptual to Learned Approaches @ EUSIPCO
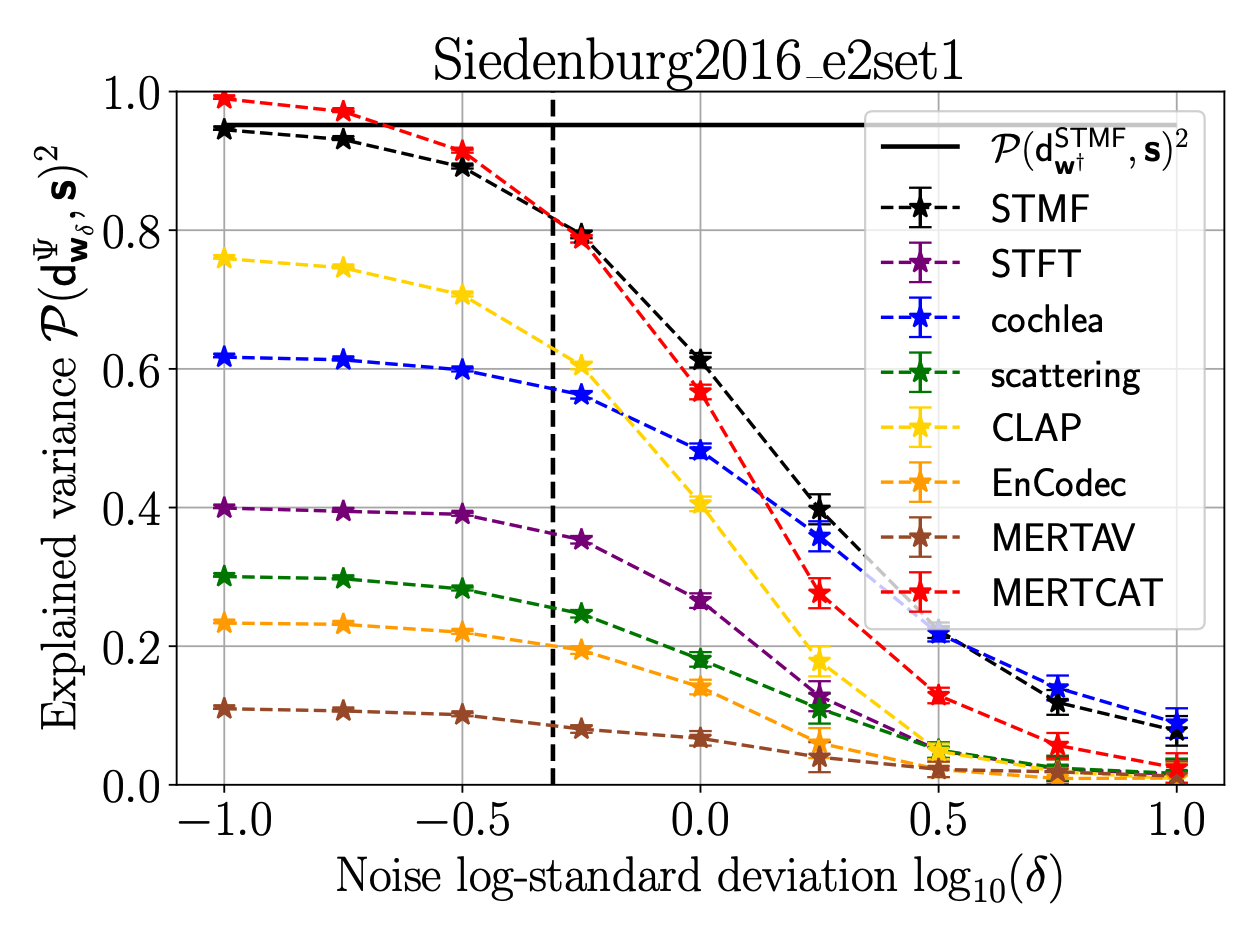
Timbre, encompassing an intricate set of acoustic cues, is key to identify sound sources, and especially to discriminate musical instruments and playing styles. Psychoacoustic studies focusing on timbre deploy massive efforts to explain human timbre perception. To uncover the acoustic substrates of timbre perceived dissimilarity, a recent work leveraged metric learning strategies on different perceptual representations and performed a meta-analysis of seventeen dissimilarity rated musical audio datasets. By learning salient patterns in very high-dimensional representations, metric learning accounts for a reasonably large part of the variance in human ratings. The present work shows that combining the most recent deep audio embeddings with a metric learning approach makes it possible to explain almost all the variance in human dissimilarity ratings. Furthermore, the robustness of the learning procedure against simulated human rating variability is thoroughly investigated. Intensive numerical experiments support the explanatory power and robustness against degraded dissimilarity ratings of the learning metric strategy using deep embeddings.
Hold Me Tight: Stable Encoder–Decoder Design for Speech Enhancement
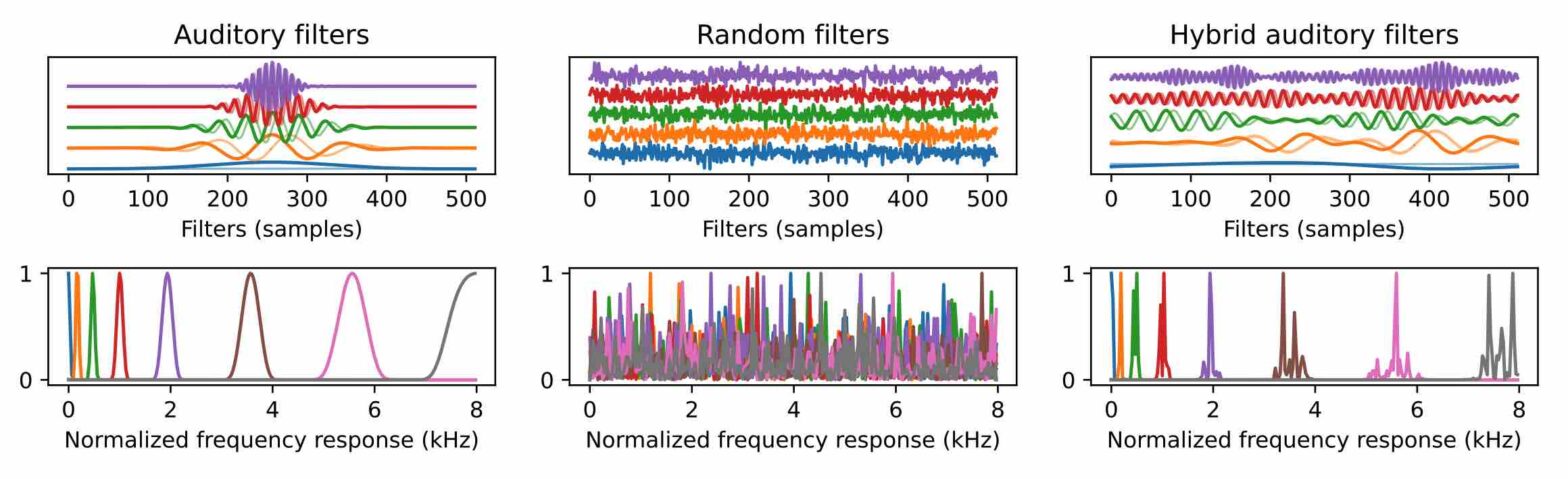
Convolutional layers with 1-D filters are often used as frontend to encode audio signals. Unlike fixed time-frequency representations, they can adapt to the local characteristics of input data. However, 1-D filters on raw audio are hard to train and often suffer from instabilities. In this paper, we address these problems with hybrid solutions, i.e., combining theory-driven and datadriven approaches. First, we preprocess the audio signals via a auditory filterbank, guaranteeing good frequency localization for the learned encoder. Second, we use results from frame theory to define an unsupervised learning objective that encourages energy conservation and perfect reconstruction. Third, we adapt mixed compressed spectral norms as learning objectives to the encoder coefficients. Using these solutions in a low-complexity encoder-mask-decoder model significantly improves the perceptual evaluation of speech quality (PESQ) in speech enhancement.
Trainable signal encoders that are robust against noise @ Inter-Noise
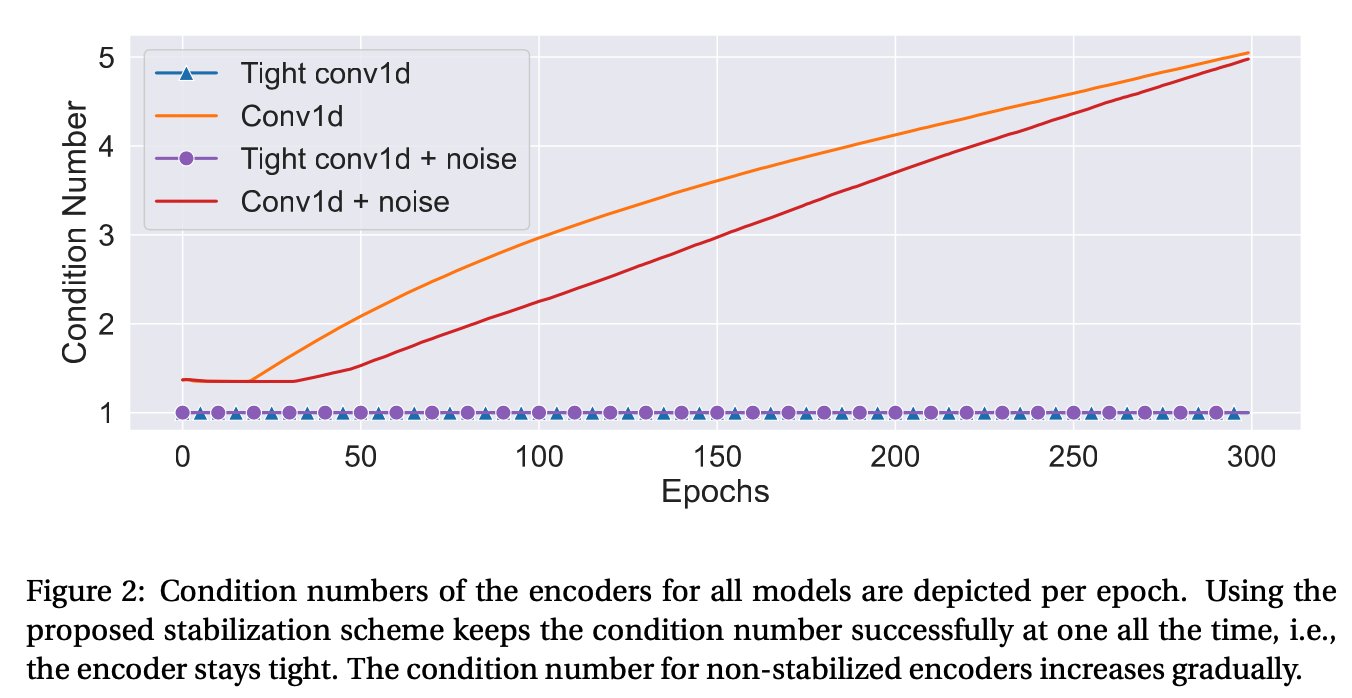
Within the deep learning paradigm, finite impulse response (FIR) filters are often used to encode audio signals, yielding flexible and adaptive feature representations. We show that a stabilization of FIR filterbanks with fixed filter lengths (convolutional layers with 1-D filters)leads to encoders that are optimally robust against noise and can be inverted with perfect reconstruction by their transposes. To maintain their flexibility as regular neural network layers, we implement the stabilization via a computationally efficient regularizing term in the objective function of the learning problem. In this way, the encoder keeps its expressive power and is optimally stable and noise-robust throughout the whole learning procedure. We show in a denoising task where noise is present in the input and in the encoder representation, that the proposed stabilization of the trainable filterbank encoder is decisive for increasing the signal-to-noise ratio of the denoised signals significantly compared to a model with a naively trained encoder.
Structure Versus Randomness in Computer Music and the Scientific Legacy of Jean-Claude Risset @ JIM

According to Jean-Claude Risset (1938–2016), “art and science bring about complementary kinds of knowledge”. In 1969, he presented his piece Mutations as “[attempting] to explore […] some of the possibilities offered by the computer to compose at the very level of sound—to compose sound itself, so to speak.” In this article, I propose to take the same motto as a starting point, yet while adopting a mathematical and technological outlook, more so than a musicological one.
Instabilities in Convnets for Raw Audio @ IEEE SPL
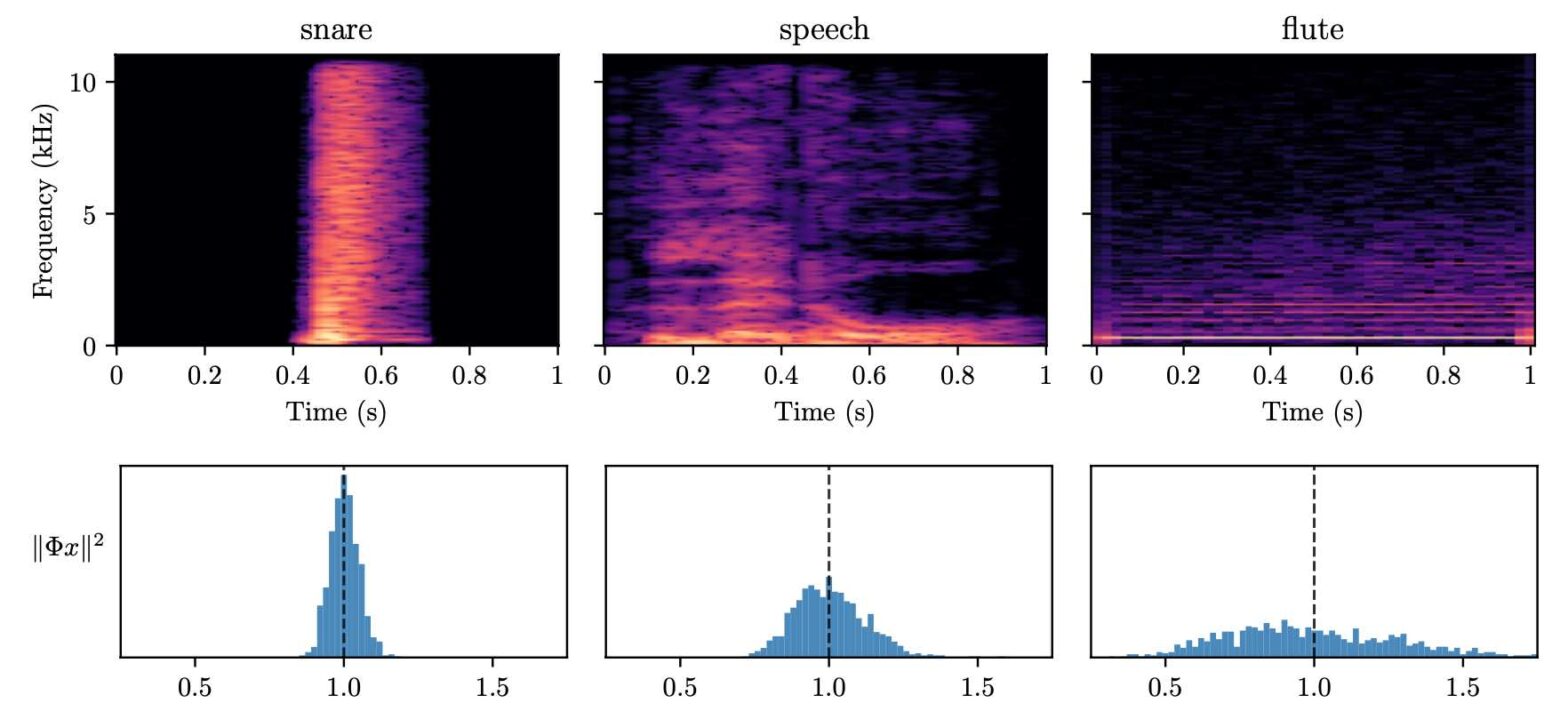
What makes waveform-based deep learning so hard? Despite numerous attempts at training convolutional neural networks (convnets) for filterbank design, they often fail to outperform hand-crafted baselines. These baselines are linear time-invariant systems: as such, they can be approximated by convnets with wide receptive fields. Yet, in practice, gradient-based optimization leads to suboptimal approximations. In our… Continue reading Instabilities in Convnets for Raw Audio @ IEEE SPL
Kymatio notebooks @ ISMIR 2023

On November 5th, 2023, we hosted a tutorial on Kymatio, entitled “Deep Learning meets Wavelet Theory for Music Signal Processing”, as part of the International Society for Music Information Retrieval (ISMIR) conference in Milan, Italy.
The Jupyter notebooks below were authored by Chris Mitcheltree and Cyrus Vahidi from Queen Mary University of London.
Mathieu, Vincent, and Modan present at DCASE

Our group has presented two challenge tasks and two papers at the international workshop on Detection and Classification of Acoustic Scenes and Events (DCASE), held in Tampere (Finland) in September 2023.