


Le son, en tant que vecteur d’information, est une aubaine pour les sciences naturelles. À l’heure des smartphones et de l’Internet des objets, il devient possible de décrire dans le détail les propriétés acoustiques d’un environnement, que celui-ci soit naturel ou industrialisé. Des algorithmes d’intelligence artificielle (IA) sont alors requis pour traiter automatiquement les données massives ainsi collectées et interagir utilement avec l’humain. Mais en pratique, un tel programme de recherche soulève des problèmes de fiabilité, de durabilité, de sécurité informatique et de mesure de l’incertitude.
Author: Vincent Lostanlen
Structure Versus Randomness in Computer Music and the Scientific Legacy of Jean-Claude Risset @ JIM

According to Jean-Claude Risset (1938–2016), “art and science bring about complementary kinds of knowledge”. In 1969, he presented his piece Mutations as “[attempting] to explore […] some of the possibilities offered by the computer to compose at the very level of sound—to compose sound itself, so to speak.” In this article, I propose to take the same motto as a starting point, yet while adopting a mathematical and technological outlook, more so than a musicological one.
Instabilities in Convnets for Raw Audio @ IEEE SPL
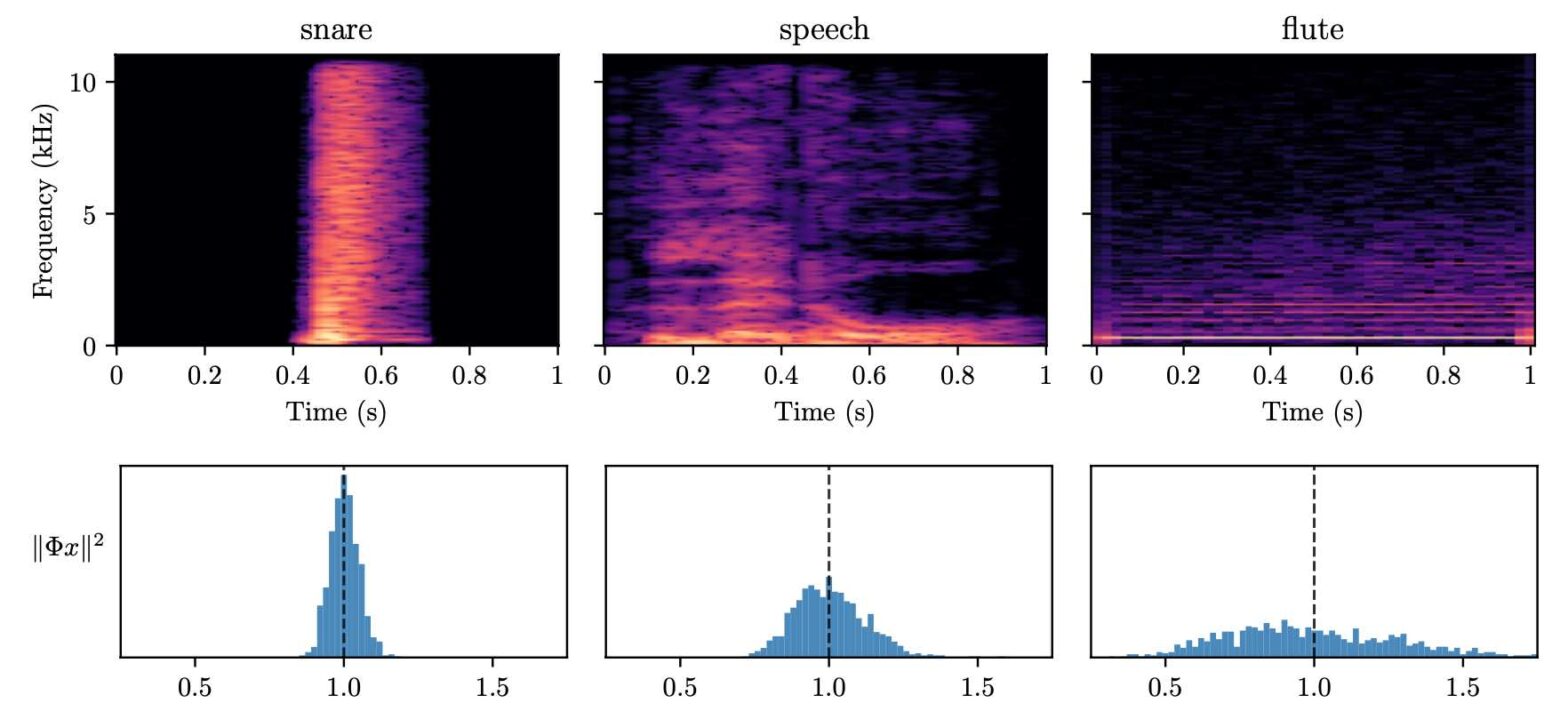
What makes waveform-based deep learning so hard? Despite numerous attempts at training convolutional neural networks (convnets) for filterbank design, they often fail to outperform hand-crafted baselines. These baselines are linear time-invariant systems: as such, they can be approximated by convnets with wide receptive fields. Yet, in practice, gradient-based optimization leads to suboptimal approximations. In our… Continue reading Instabilities in Convnets for Raw Audio @ IEEE SPL
PhD offer: Machine learning on solar-powered environmental sensors

Many biological and geophysical phenomena follow a near-periodic day-night cycle, known as circadian rhythm. When designing AI-enabled autonomous sensors for environmental modeling, this circadian rhythm poses both a challenge and an opportunity.
Bibliothécaire musical : un métier en transition ?

L’Association pour la Coopération des professionnels de l’Information musicale (ACIM) organise son congrès 2024 à Orléans. Le thème ce cette année est : “Bibliothécaire musical : un métier en transition ?”.
PhD offer: Developmental robotics of birdsong

The Neurocybernetic team of ETIS Lab (CNRS, CY Cergy-Paris University, ENSEA) is seeking applicants for a fully funded PhD place providing an exciting opportunity to pursue a postgraduate research in the fields of bio/neuro-inspired robotics, ethology, neuroscience.Webpage: https://www.etis-lab.fr/neuro/ This PhD is funded by the French ANR, under the 4 years’ project “Nirvana” on sensorimotor integration of… Continue reading PhD offer: Developmental robotics of birdsong
27-28 mars 2024 : GreenDays à l’IRIT
En partenariat avec GDS Ecoinfo et cinq autres GDR, nous organisons les journées GreenDays 2024 à Toulouse, les 27 et 28 mars 2024, sur le thème “Explorer les multiples facettes de la sobriété numérique”.
8 février 2024 : “Les sens artificiels” au Stereolux

Le jeudi 8 février 2024 à 18h30 au Stereolux, dans le cadre de la Nuit blanche des chercheur-e-s de Nantes université.
L’intelligence artificielle (IA) révolutionne notre compréhension du vivant en utilisant les sens humains. Elle permet une analyse poussée de la parole, des signaux sonores et de la bioacoustique. En médecine, les sens peuvent être reproduits pour améliorer les diagnostics. Dans la nature, les sens peuvent être simulés pour améliorer la compréhension du vivant. Au cours de cette session animée par des expert·es renommé·es, explorez les avancées de l’IA pour la santé et le vivant du futur.
Wébinaire WEAMEC “Environnement et EMR”
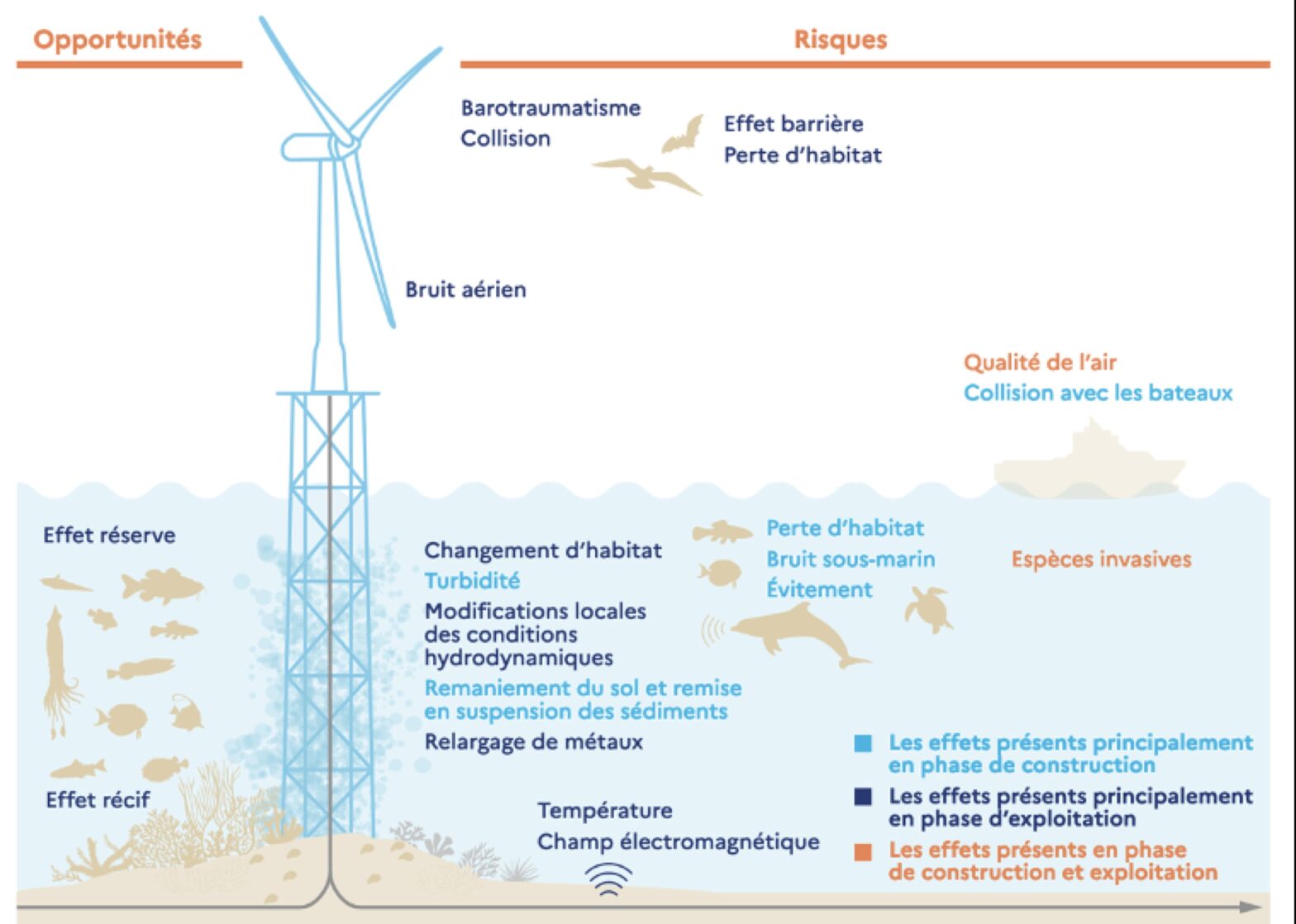
Dans le cadre des projets CAPTEO et PETREL, Vincent Lostanlen participe à un webinaire WEAMEC afin de présenter l’état de l’art en écoconception de capteur bioacoustique avec IA embarquée pour le suivi environnemental des énergies marines renouvelables.
Kymatio notebooks @ ISMIR 2023

On November 5th, 2023, we hosted a tutorial on Kymatio, entitled “Deep Learning meets Wavelet Theory for Music Signal Processing”, as part of the International Society for Music Information Retrieval (ISMIR) conference in Milan, Italy.
The Jupyter notebooks below were authored by Chris Mitcheltree and Cyrus Vahidi from Queen Mary University of London.