

Dans le cadre de l’action « Traitement du signal pour l’audio et l’écoute artificielle » du GdR ISIS, nous organisons, le Jeudi 16 Novembre 2023 à l’IRCAM, une troisième journée dédiée au traitement des signaux de musique
Tag: time-frequency
Apprentissage de variété riemannienne pour l’analyse-synthèse de signaux non stationnaires @ GRETSI
Spectral trancoder: using pretrained urban sound classifiers on undersampled spectral representations @ DCASE
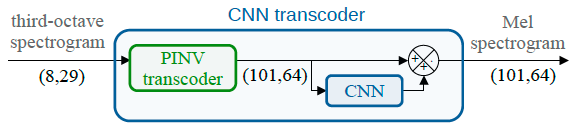
Slow or fast third-octave bands representations (with a frame resp. every 1-s and 125-ms) have been a de facto standard for urban acoustics, used for example in long-term monitoring applications. It has the advantages of requiring few storage capabilities and of preserving privacy. As most audio classification algorithms take Mel spectral representations with very fast… Continue reading Spectral trancoder: using pretrained urban sound classifiers on undersampled spectral representations @ DCASE
Mesostructures: Beyond spectrogram loss in differentiable time-frequency analysis @ JAES
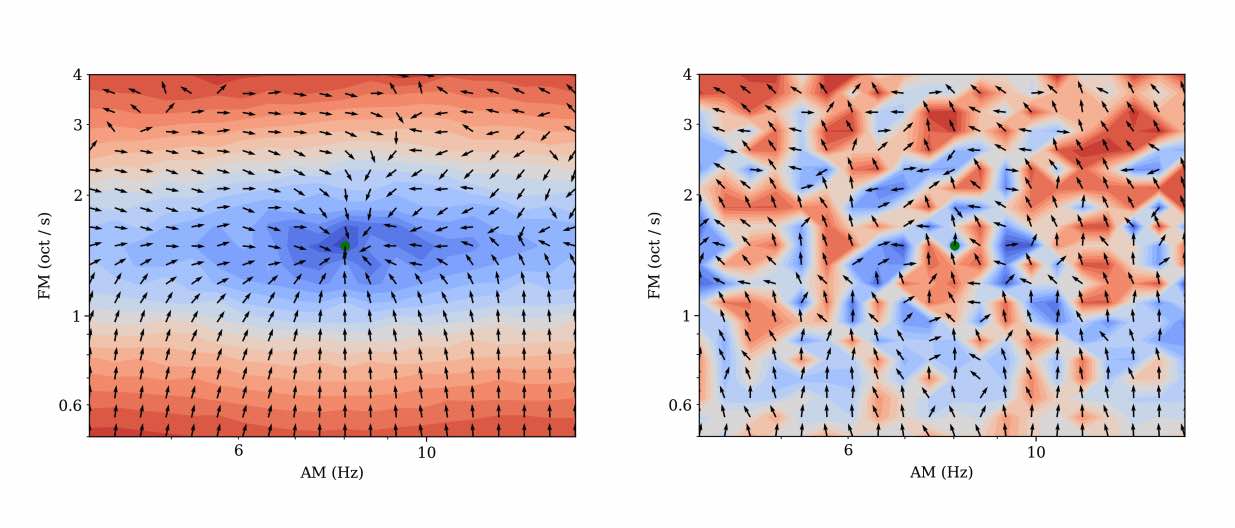
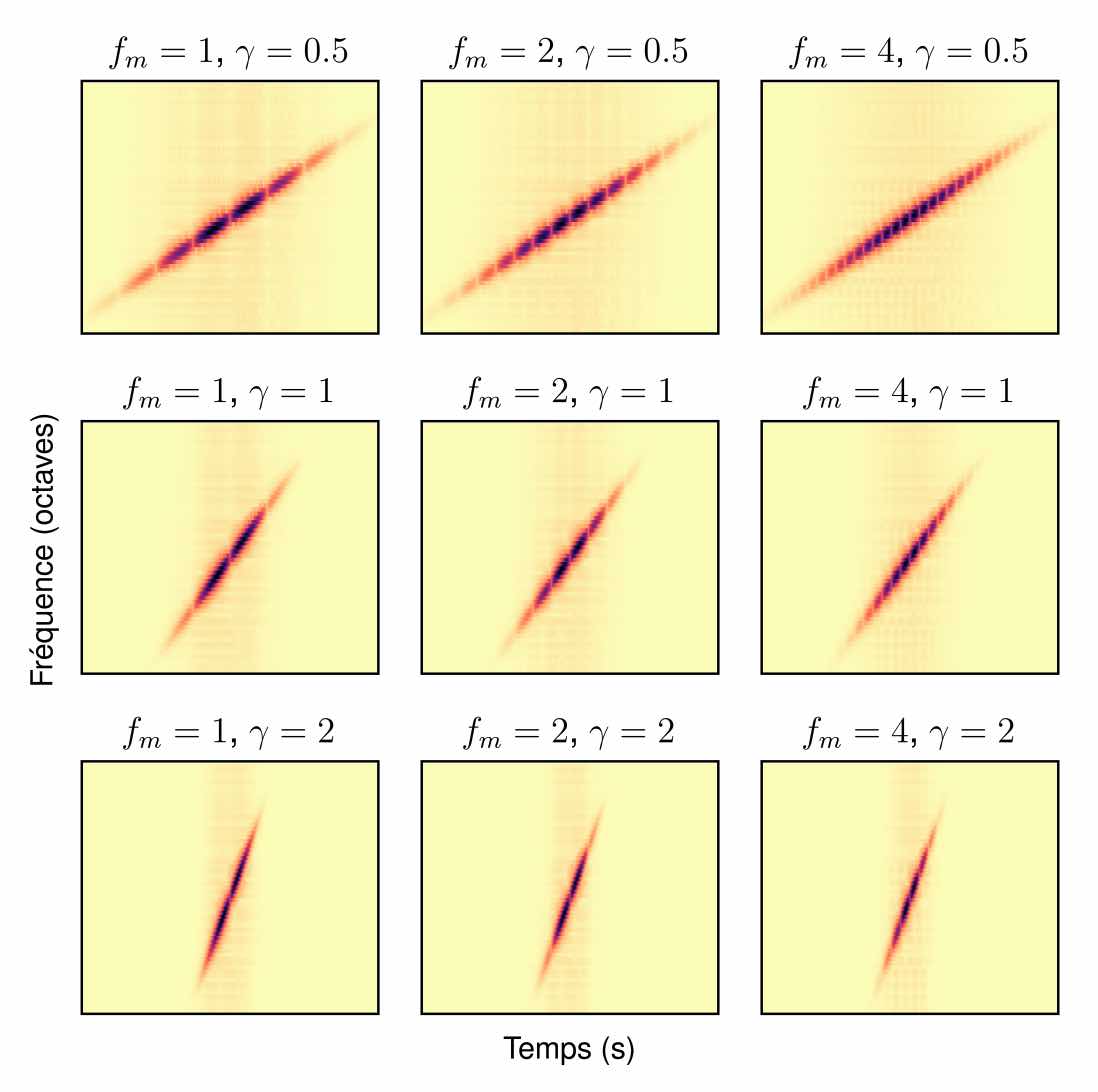
Computer musicians refer to mesostructures as the intermediate levels of articulation between the microstructure of waveshapes and the macrostructure of musical forms. Examples of mesostructures include melody, arpeggios, syncopation, polyphonic grouping, and textural contrast. Despite their central role in musical expression, they have received limited attention in recent applications of deep learning to the analysis and synthesis of musical audio. Currently, autoencoders and neural audio synthesizers are only trained and evaluated at the scale of microstructure: i.e., local amplitude variations up to 100 milliseconds or so. In this paper, we formulate and address the problem of mesostructural audio modeling via a composition of a differentiable arpeggiator and time-frequency scattering. We empirically demonstrate that time-frequency scattering serves as a differentiable model of similarity between synthesis parameters that govern mesostructure. By exposing the sensitivity of short-time spectral distances to time alignment, we motivate the need for a time-invariant and multiscale differentiable time-frequency model of similarity at the level of both local spectra and spectrotemporal modulations.
Fitting Auditory Filterbanks with MuReNN @ IEEE WASPAA
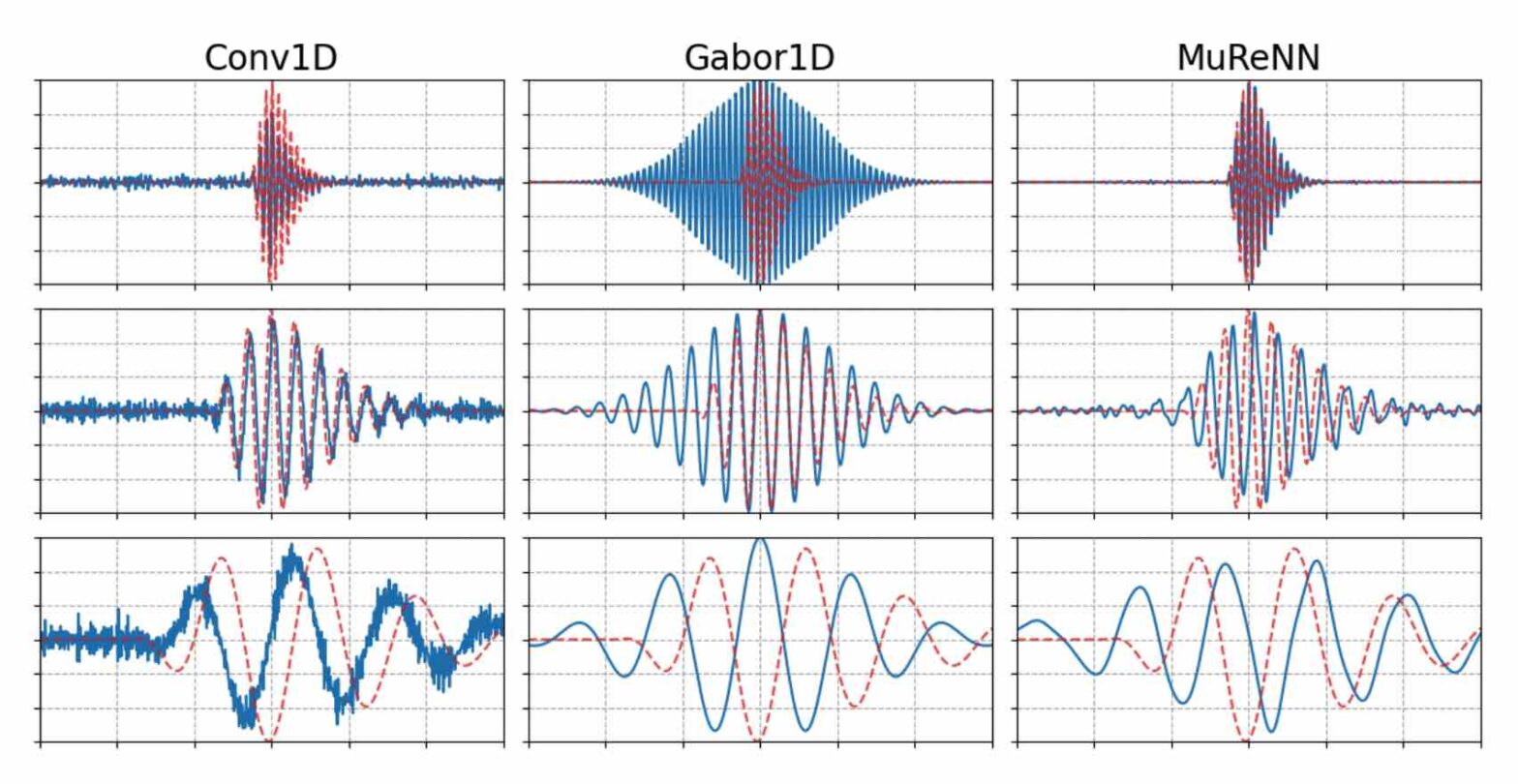
Waveform-based deep learning faces a dilemma between nonparametric and parametric approaches. On one hand, convolutional neural networks (convnets) may approximate any linear time-invariant system; yet, in practice, their frequency responses become more irregular as their receptive fields grow. On the other hand, a parametric model such as LEAF is guaranteed to yield Gabor filters, hence an optimal time-frequency localization; yet, this strong inductive bias comes at the detriment of representational capacity. In this paper, we aim to overcome this dilemma by introducing a neural audio model, named multiresolution neural network (MuReNN). The key idea behind MuReNN is to train separate convolutional operators over the octave subbands of a discrete wavelet transform (DWT). Since the scale of DWT atoms grows exponentially between octaves, the receptive fields of the subsequent learnable convolutions in MuReNN are dilated accordingly. For a given real-world dataset, we fit the magnitude response of MuReNN to that of a wellestablished auditory filterbank: Gammatone for speech, CQT for music, and third-octave for urban sounds, respectively. This is a form of knowledge distillation (KD), in which the filterbank “teacher” is engineered by domain knowledge while the neural network “student” is optimized from data. We compare MuReNN to the state of the art in terms of goodness of fit after KD on a hold-out set and in terms of Heisenberg time-frequency localization. Compared to convnets and Gabor convolutions, we find that MuReNN reaches state-of-the-art performance on all three optimization problems.
PhD offer: “Theory and implementation of multi-resolution neural networks”
The French national center for scientific research (CNRS) is hiring a PhD student as part of a three-year project on “Multi-Resolution Neural Networks” (MuReNN). MuReNN is supported by the French national funding agency (ANR), and hosted at the Laboratoire des Sciences du Numérique de Nantes (LS2N). A collaboration with the Austrian Academy of Sciences is… Continue reading PhD offer: “Theory and implementation of multi-resolution neural networks”
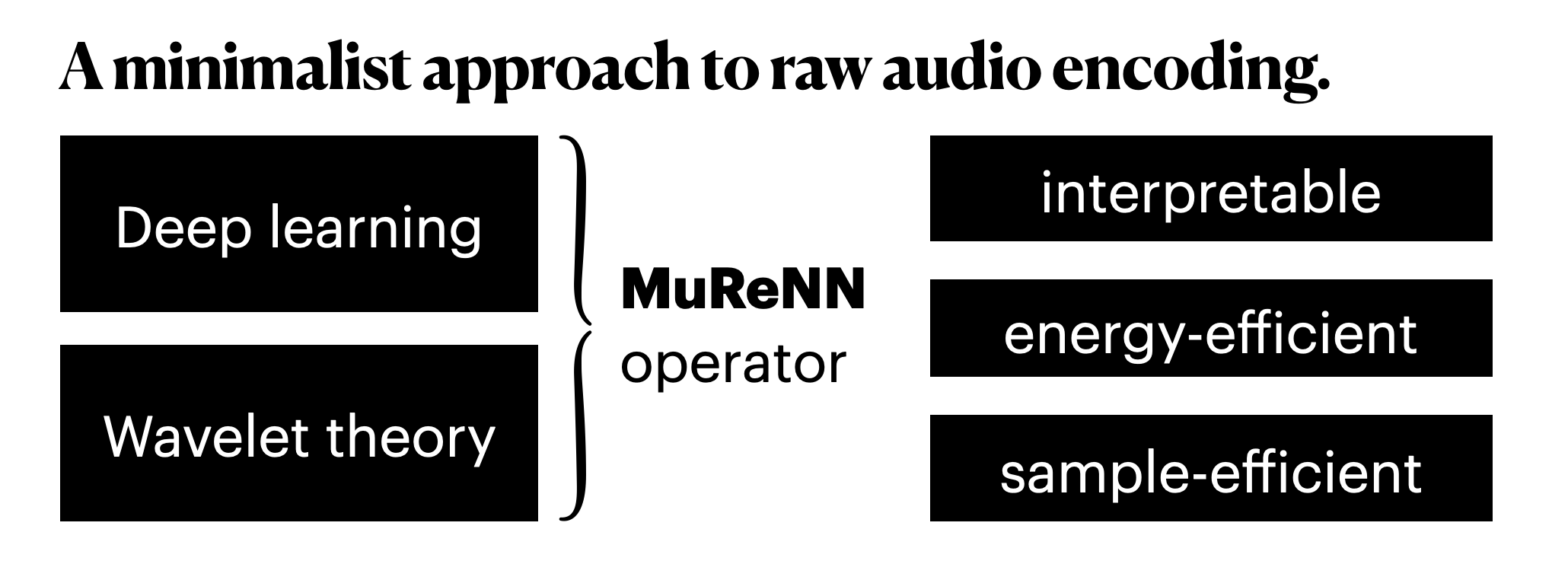
MuReNN: Multi-Resolution Neural Networks
“Less is more”, once the foundational motto of minimalist art, is making its way into artificial intelligence. After a maximalist decade of larger computers training larger neural networks on larger datasets (2012-2022), a countertrend arises. What if human-level performance could be achieved with less computing, less memory, and less supervision? In deep learning, the research… Continue reading MuReNN: Multi-Resolution Neural Networks
Announcing Kymatio tutorial @ ISMIR
We will present a tutorial on Kymatio at the International Society for Music Information Retrieval (ISMIR) Conference, held in Milan on November 5-9, 2023.
Kymatio: Deep Learning meets Wavelet Theory for Music Signal Processing