


“STONE: Self-supervised tonality estimator”, at École Centrale de Nantes, amphi E, 2pm.
Tag: music
STONE: Self-supervised tonality estimator @ ISMIR
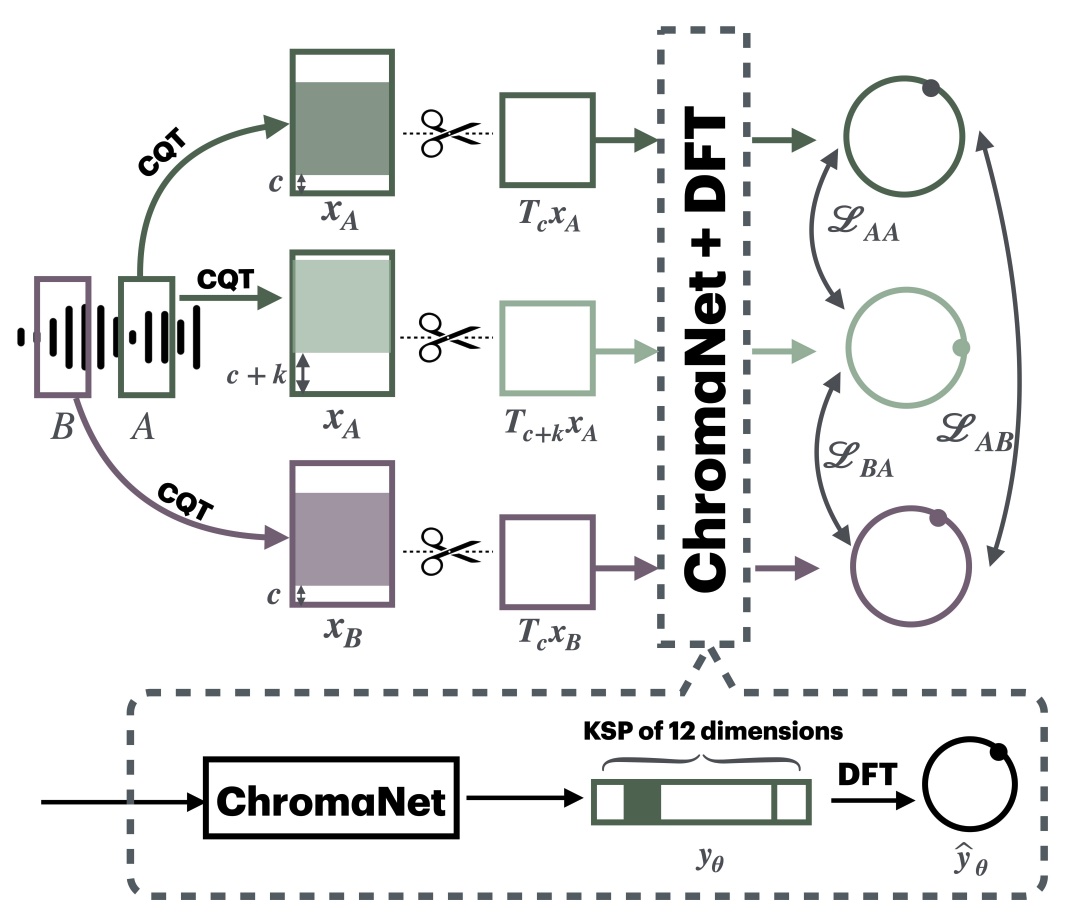
Although deep neural networks can estimate the key of a musical piece, their supervision incurs a massive annotation effort. Against this shortcoming, we present STONE, the first self-supervised tonality estimator. The architecture behind STONE, named ChromaNet, is a convnet with octave equivalence which outputs a “key signature profile” (KSP) of 12 structured logits. First, we train ChromaNet to regress artificial pitch transpositions between any two unlabeled musical excerpts from the same audio track, as measured as cross-power spectral density (CPSD) within the circle of fifths (CoF). We observe that this self-supervised pretext task leads KSP to correlate with tonal key signature. Based on this observation, we extend STONE to output a structured KSP of 24 logits, and introduce supervision so as to disambiguate major versus minor keys sharing the same key signature. Applying different amounts of supervision yields semi-supervised and fully supervised tonality estimators: i.e., Semi-TONEs and Sup-TONEs. We evaluate these estimators on FMAK, a new dataset of 5489 real-world musical recordings with expert annotation of 24 major and minor keys. We find that Semi-TONE matches the classification accuracy of Sup-TONE with reduced supervision and outperforms it with equal supervision.
EMVD dataset: a dataset of extreme vocal distortion techniques used in heavy metal @ CBMI
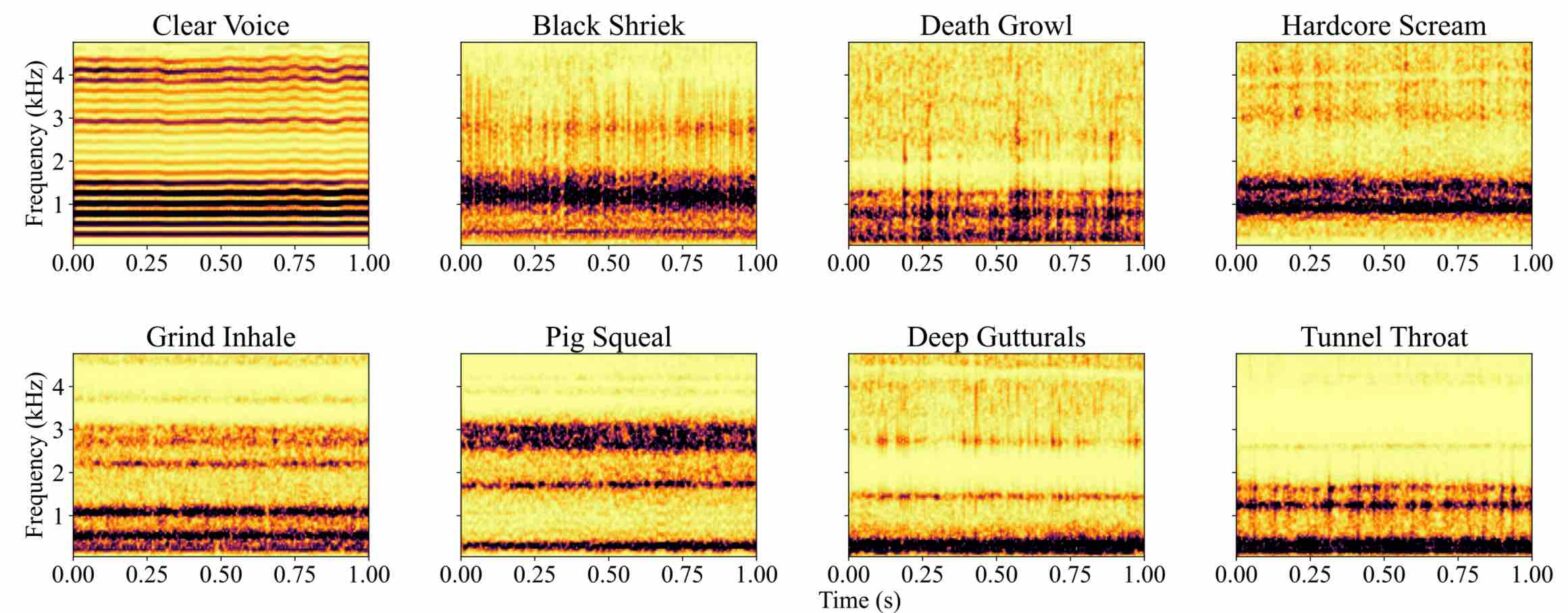
In this paper, we introduce the Extreme Metal Vocals Dataset, which comprises a collection of recordings of extreme vocal techniques performed within the realm of heavy metal music. The dataset consists of 760 audio excerpts of 1 second to 30 seconds long, totaling about 100 min of audio material, roughly composed of 60 minutes of distorted voices and 40 minutes of clear voice recordings. These vocal recordings are from 27 different singers and are provided without accompanying musical instruments or post-processing effects. The distortion taxonomy within this dataset encompasses four distinct distortion techniques and three vocal effects, all performed in different pitch ranges. Performance of a state-of-the-art deep learning model is evaluated for two different classification tasks related to vocal techniques, demonstrating the potential of this resource for the audio processing community.
On the Robustness of Musical Timbre Perception Models: From Perceptual to Learned Approaches @ EUSIPCO
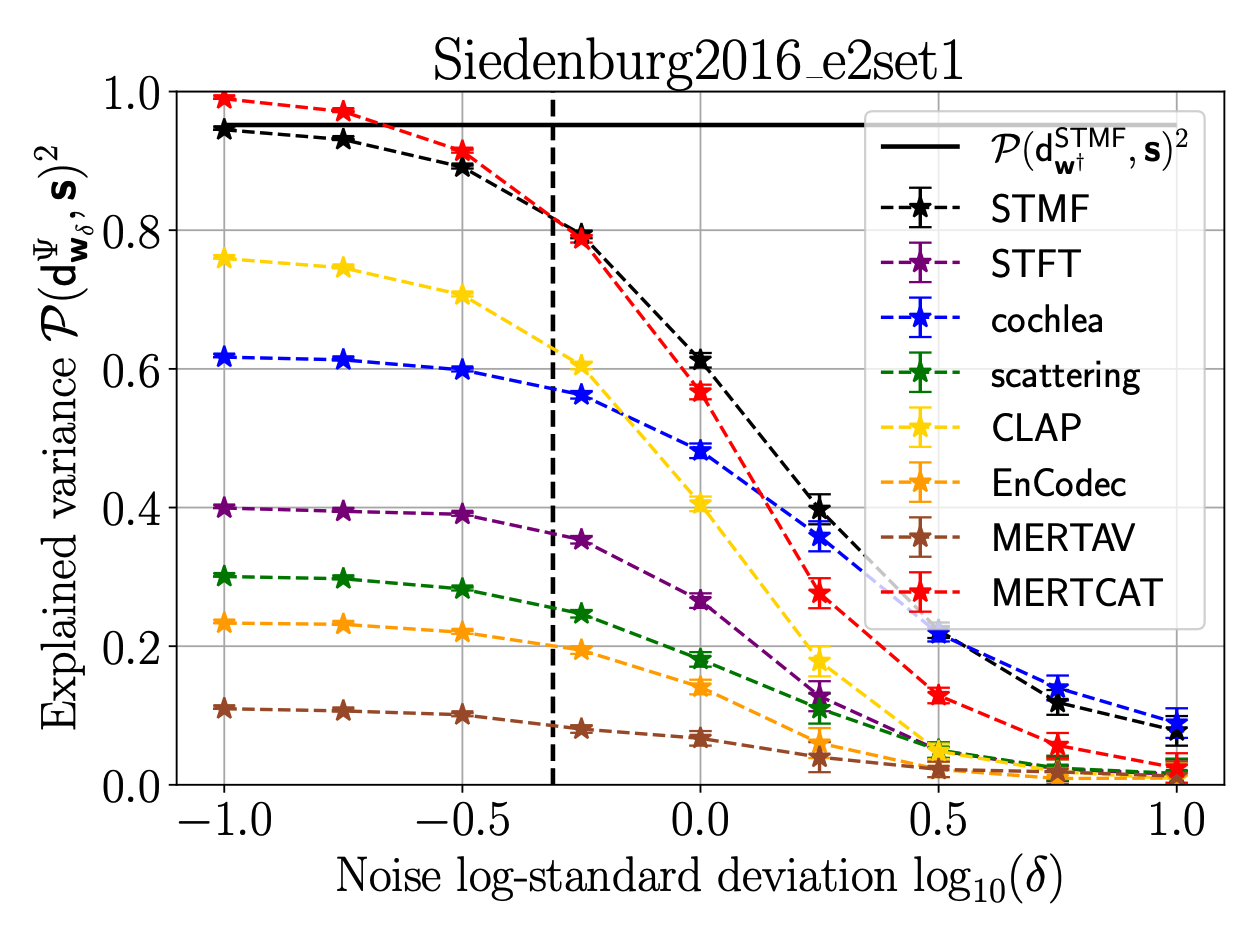
Timbre, encompassing an intricate set of acoustic cues, is key to identify sound sources, and especially to discriminate musical instruments and playing styles. Psychoacoustic studies focusing on timbre deploy massive efforts to explain human timbre perception. To uncover the acoustic substrates of timbre perceived dissimilarity, a recent work leveraged metric learning strategies on different perceptual representations and performed a meta-analysis of seventeen dissimilarity rated musical audio datasets. By learning salient patterns in very high-dimensional representations, metric learning accounts for a reasonably large part of the variance in human ratings. The present work shows that combining the most recent deep audio embeddings with a metric learning approach makes it possible to explain almost all the variance in human dissimilarity ratings. Furthermore, the robustness of the learning procedure against simulated human rating variability is thoroughly investigated. Intensive numerical experiments support the explanatory power and robustness against degraded dissimilarity ratings of the learning metric strategy using deep embeddings.
Culture et patrimoine numérique @ Nantes Digital Week

de 9h30 à 7h au Château des ducs de Bretagne à Nantes.
11h15. Vincent LOSTANLEN. “Le streaming, est-ce que ça pollue ?” : pour une écologie de la musique numérique.
Phantasmagoria: Sound Synthesis After the Turing Test @ S4

Sound synthesis with computers is often described as a Turing test or “imitation game”. In this context, a passing test is regarded by some as evidence of machine intelligence and by others as damage to human musicianship. Yet, both sides agree to judge synthesizers on a perceptual scale from fake to real. My article rejects this premise and borrows from philosopher Clément Rosset’s “L’Objet singulier” (1979) and “Fantasmagories” (2006) to affirm (1) the reality of all music, (2) the infidelity of all audio data, and (3) the impossibility of strictly repeating sensations. Compared to analog tape manipulation, deep generative models are neither more nor less unfaithful. In both cases, what is at stake is not to deny reality via illusion but to cultivate imagination as “function of the unreal” (Bachelard); i.e., a precise aesthetic grip on reality. Meanwhile, i insist that digital music machines are real objects within real human societies: their performance on imitation games should not exonerate us from studying their social and ecological impacts.
Learning to Solve Inverse Problems for Perceptual Sound Matching @ IEEE TASLP
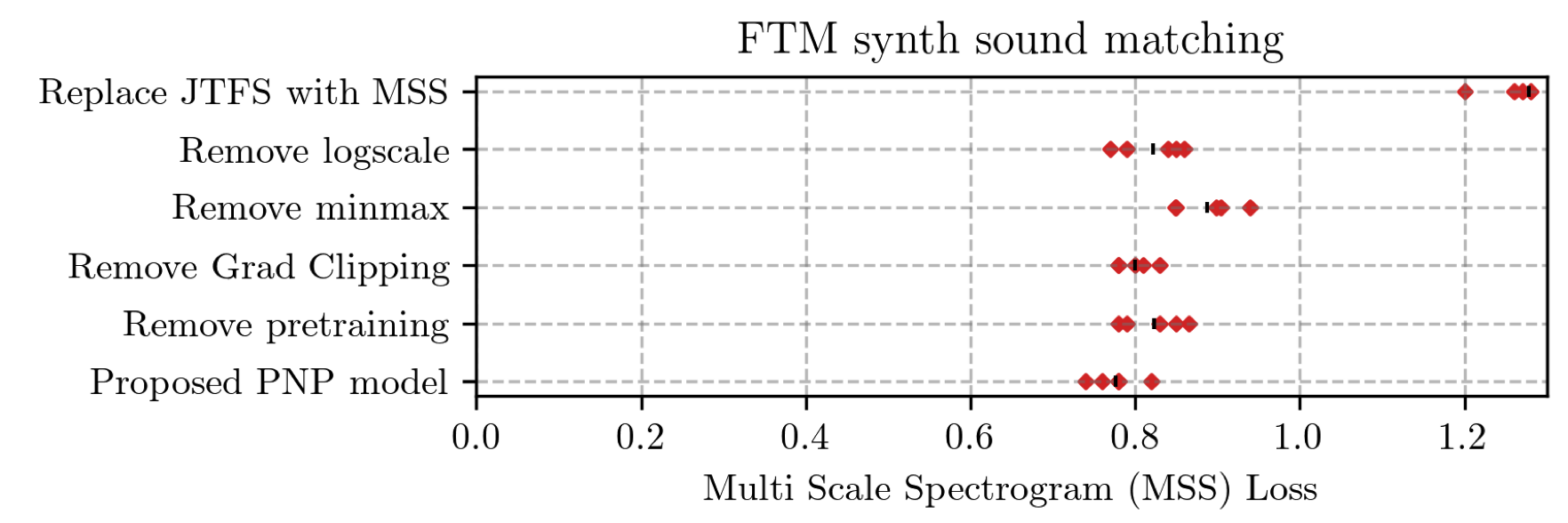
Perceptual sound matching (PSM) aims to find the input parameters to a synthesizer so as to best imitate an audio target. Deep learning for PSM optimizes a neural network to analyze and reconstruct prerecorded samples. In this context, our article addresses the problem of designing a suitable loss function when the training set is generated by a differentiable synthesizer. Our main contribution is perceptual–neural–physical loss (PNP), which aims at addressing a tradeoff between perceptual relevance and computational efficiency. The key idea behind PNP is to linearize the effect of synthesis parameters upon auditory features in the vicinity of each training sample. The linearization procedure is massively parallelizable, can be precomputed, and offers a 100-fold speedup during gradient descent compared to differentiable digital signal processing (DDSP). We show that PNP is able to accelerate DDSP with joint time–frequency scattering transform (JTFS) as auditory feature while preserving its perceptual fidelity. Additionally, we evaluate the impact of other design choices in PSM: parameter rescaling, pretraining, auditory representation, and gradient clipping. We report state-of-the-art results on both datasets and find that PNP-accelerated JTFS has greater influence on PSM performance than any other design choice.
Model-Based Deep Learning for Music Information Research @ IEEE SPM
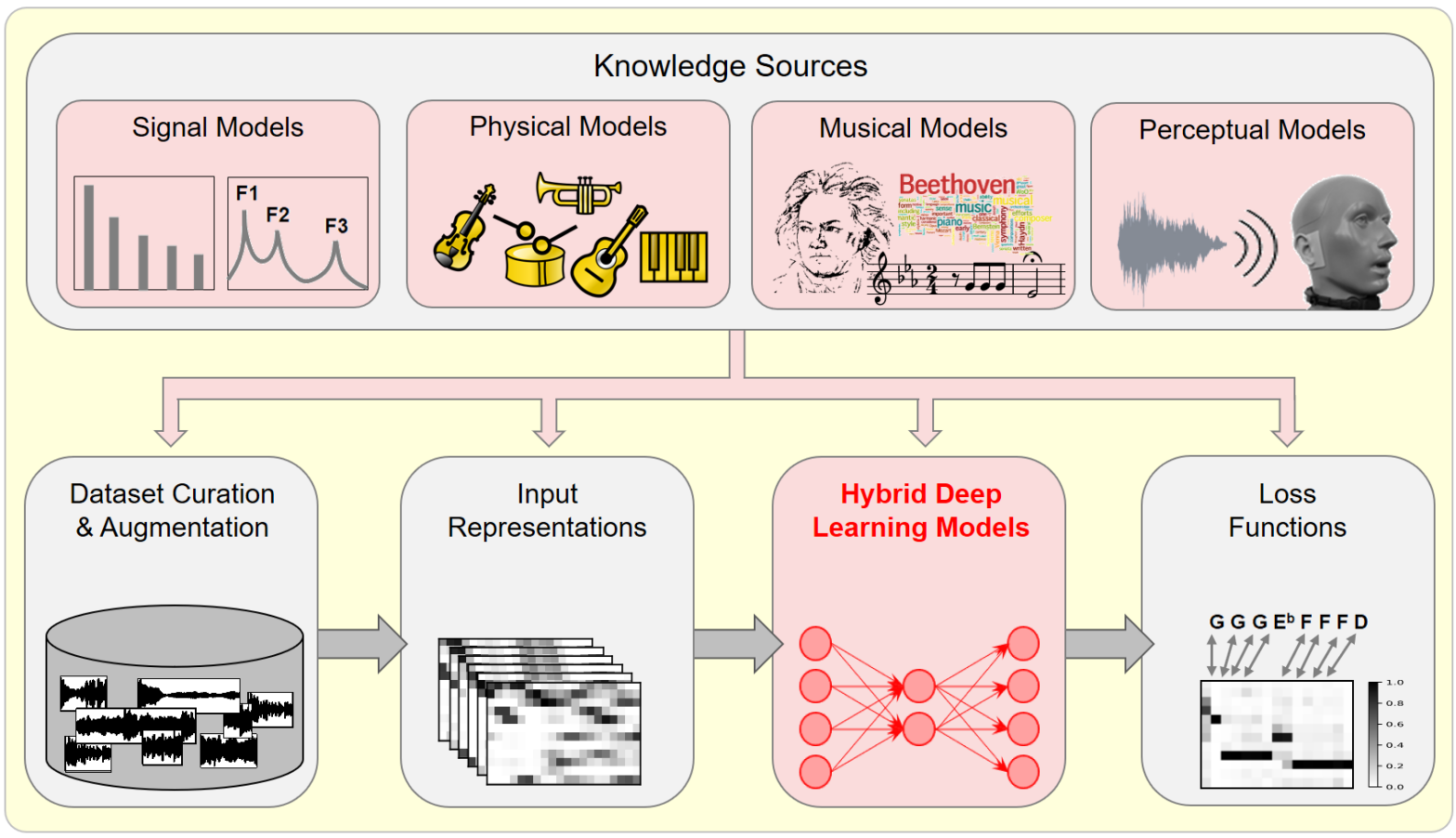
In this article, we investigate the notion of model-based deep learning in the realm of music information research (MIR). Loosely speaking, we refer to the term model-based deep learning for approaches that combine traditional knowledge-based methods with data-driven techniques, especially those based on deep learning, within a diff erentiable computing framework. In music, prior knowledge for instance related to sound production, music perception or music composition theory can be incorporated into the design of neural networks and associated loss functions. We outline three specific scenarios to illustrate the application of model-based deep learning in MIR, demonstrating the implementation of such concepts and their potential.
Action “Musiscale” au symposium du GDR MaDICS
Le 30 mai 2024 à Blois, se tenait le sixième symposium du GDR MaDICS : masses de données, informations et connaissances en sciences. Dans le cadre de l’action “Musiscale : modélisation multi-échelles de masses de données musicales”, j’ai présenté les travaux de l’équipe sur la diffusion en ondelettes (scattering transform) ainsi que sur les réseaux de neurones multirésolution (MuReNN pour multi-resolution neural networks).
Towards multisensory control of physical modeling synthesis @ Inter-Noise

Physical models of musical instruments offer an interesting tradeoff between computational efficiency and perceptual fidelity. Yet, they depend on a multidimensional space of user-defined parameters whose exploration by trial and error is impractical. Our article addresses this issue by combining two ideas: query by example and gestural control. On one hand, we train a deep… Continue reading Towards multisensory control of physical modeling synthesis @ Inter-Noise