


Audio has long been a key component of multimedia research. As far as indexing is concerned, the research and industrial context has changed drastically in the last 20 years or so. Today, applications of audio indexing range from karaoke applications to singing voice synthesis and creative audio design. This special session aims at bringing together researchers that aim at proposing new tools or paradigms to investigate audio and music processing in the context of indexation and corpus-based generation.
Tag: in English
This post is available in English.
Trainable signal encoders that are robust against noise @ Inter-Noise
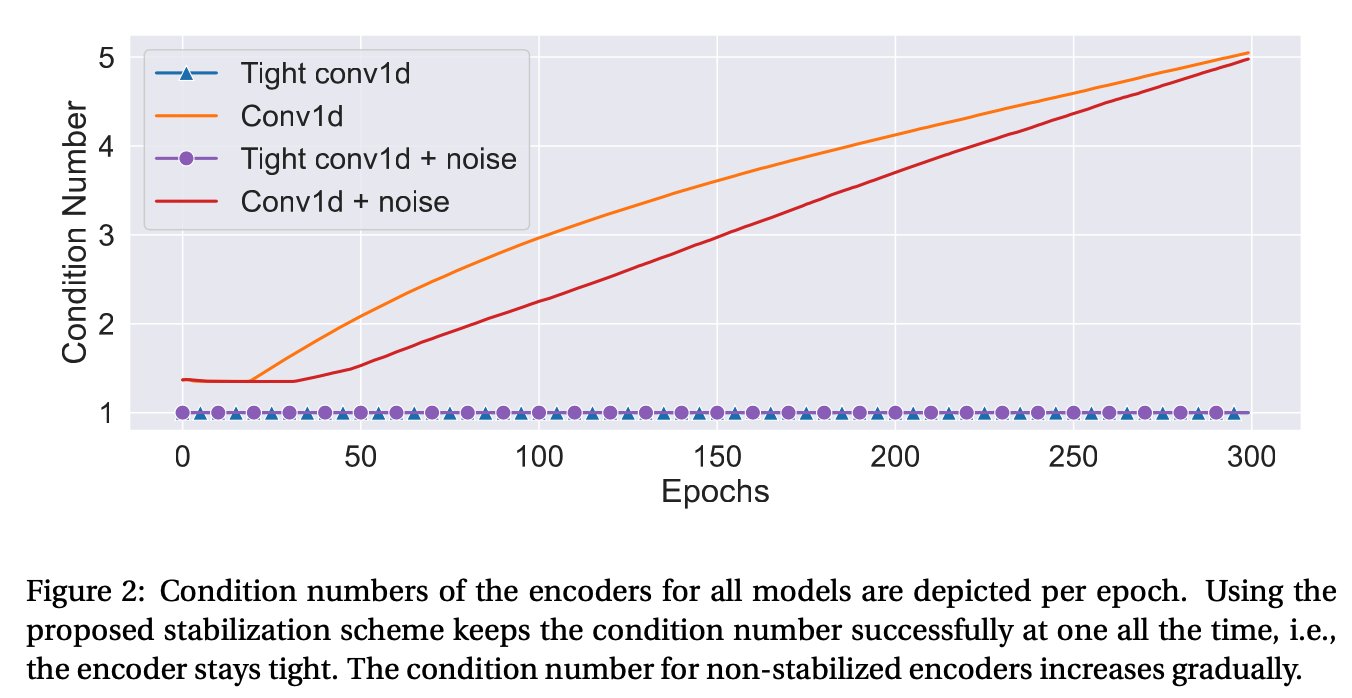
Within the deep learning paradigm, finite impulse response (FIR) filters are often used to encode audio signals, yielding flexible and adaptive feature representations. We show that a stabilization of FIR filterbanks with fixed filter lengths (convolutional layers with 1-D filters)leads to encoders that are optimally robust against noise and can be inverted with perfect reconstruction by their transposes. To maintain their flexibility as regular neural network layers, we implement the stabilization via a computationally efficient regularizing term in the objective function of the learning problem. In this way, the encoder keeps its expressive power and is optimally stable and noise-robust throughout the whole learning procedure. We show in a denoising task where noise is present in the input and in the encoder representation, that the proposed stabilization of the trainable filterbank encoder is decisive for increasing the signal-to-noise ratio of the denoised signals significantly compared to a model with a naively trained encoder.
International Workshop on Vocal Interactivity in-and-between Humans, Animals and Robots (VIHAR)
The 6th edition of the VIHAR workshop will be held in Kos, Greece, as a satellite event of INTERSPEECH. Vincent will chair one of the sessions and present a short paper named Towards Differentiable Motor Control of Bird Vocalizations. Official website: http://vihar-2024.vihar.org
BirdVoxDetect: Large-Scale Detection and Classification of Flight Calls for Bird Migration Monitoring @ IEEE TASLP
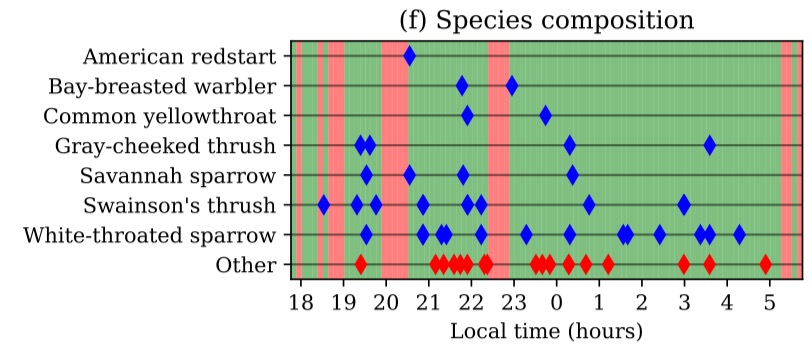
Sound event classification has the potential to advance our understanding of bird migration. Although it is long known that migratory species have a vocal signature of their own, previous work on automatic flight call classification has been limited in robustness and scope: e.g., covering few recording sites, short acquisition segments, and simplified biological taxonomies. In this paper, we present BirdVoxDetect (BVD), the first full-fledged solution to bird migration monitoring from acoustic sensor network data.
Loïc demonstrates his FTM Synthesizer on Erae Touch

A demonstration by independent researcher Loïc Jankowiak, who visited LS2N in 2023 and 2024 as part of the ApEx project of Han Han.
This is an in-progress build of a physically-modelled drum synthesizer using the Functional Transformation Method (FTM), with external MIDI control. The Embodme Erae Touch control surface is used for the velocity and impact position on the virtual drum’s surface, and the Behringer X-Touch Mini is used for controlling the various parameters of the physical model, i.e. the material properties.
Mixture of Mixups for Multi-label Classification of Rare Anuran Sounds @ EUSIPCO
Multi-label imbalanced classification poses a significant challenge in machine learning, particularly evident in bioacoustics where animal sounds often co-occur, and certain sounds are much less frequent than others. This paper focuses on the specific case of classifying anuran species sounds using the dataset AnuraSet, that contains both class imbalance and multi-label examples. To address these challenges, we introduce Mixture of Mixups (Mix2), a framework that leverages mixing regularization methods Mixup, Manifold Mixup, and MultiMix. Experimental results show that these methods, individually, may lead to suboptimal results; however, when applied randomly, with one selected at each training iteration, they prove effective in addressing the mentioned challenges, particularly for rare classes with few occurrences. Further analysis reveals that the model trained using Mix2 is also proficient in classifying sounds across various levels of class co-occurrences.
Phantasmagoria: Sound Synthesis After the Turing Test @ S4

Sound synthesis with computers is often described as a Turing test or “imitation game”. In this context, a passing test is regarded by some as evidence of machine intelligence and by others as damage to human musicianship. Yet, both sides agree to judge synthesizers on a perceptual scale from fake to real. My article rejects this premise and borrows from philosopher Clément Rosset’s “L’Objet singulier” (1979) and “Fantasmagories” (2006) to affirm (1) the reality of all music, (2) the infidelity of all audio data, and (3) the impossibility of strictly repeating sensations. Compared to analog tape manipulation, deep generative models are neither more nor less unfaithful. In both cases, what is at stake is not to deny reality via illusion but to cultivate imagination as “function of the unreal” (Bachelard); i.e., a precise aesthetic grip on reality. Meanwhile, i insist that digital music machines are real objects within real human societies: their performance on imitation games should not exonerate us from studying their social and ecological impacts.
Machine listening symposium at World Ecoacoustics Congress

The 10th edition of the World Ecoacoustics Congress was held in Madrid between July 8th and July 12th. In this context, Juan Sebastián Ulloa and myslef have co-organized a special 3-hour symposium titled “Machine listening meets passive acoustic monitoring”. This event is supported by CAPTEO and PETREL projects.
WeAMEC PETREL project presented at Seanergy

Seanergy, the leading international event on offshore renewables energy, had its 2024 edition at Parc des expositions in Nantes.
As part of the PETREL project, i have presented a poster with the title: “Towards the sustainable design of smart acoustic sensors for environmental monitoring of offshore renewables”. We reproduce the abstract below.
Learning to Solve Inverse Problems for Perceptual Sound Matching @ IEEE TASLP
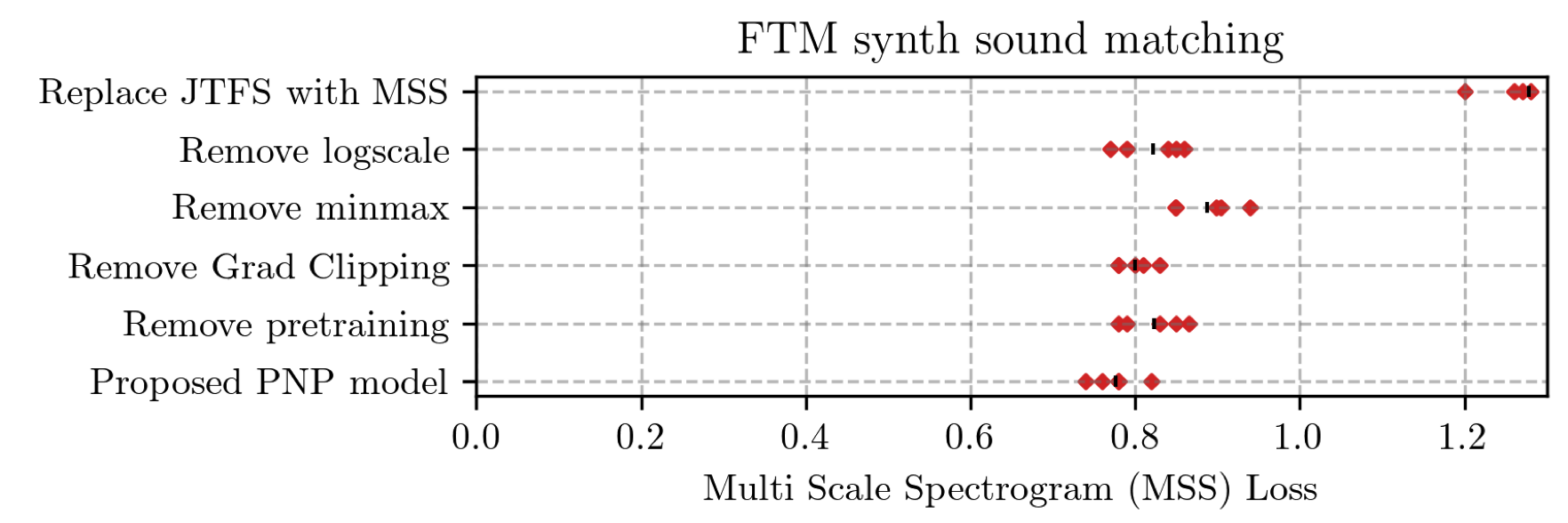
Perceptual sound matching (PSM) aims to find the input parameters to a synthesizer so as to best imitate an audio target. Deep learning for PSM optimizes a neural network to analyze and reconstruct prerecorded samples. In this context, our article addresses the problem of designing a suitable loss function when the training set is generated by a differentiable synthesizer. Our main contribution is perceptual–neural–physical loss (PNP), which aims at addressing a tradeoff between perceptual relevance and computational efficiency. The key idea behind PNP is to linearize the effect of synthesis parameters upon auditory features in the vicinity of each training sample. The linearization procedure is massively parallelizable, can be precomputed, and offers a 100-fold speedup during gradient descent compared to differentiable digital signal processing (DDSP). We show that PNP is able to accelerate DDSP with joint time–frequency scattering transform (JTFS) as auditory feature while preserving its perceptual fidelity. Additionally, we evaluate the impact of other design choices in PSM: parameter rescaling, pretraining, auditory representation, and gradient clipping. We report state-of-the-art results on both datasets and find that PNP-accelerated JTFS has greater influence on PSM performance than any other design choice.