

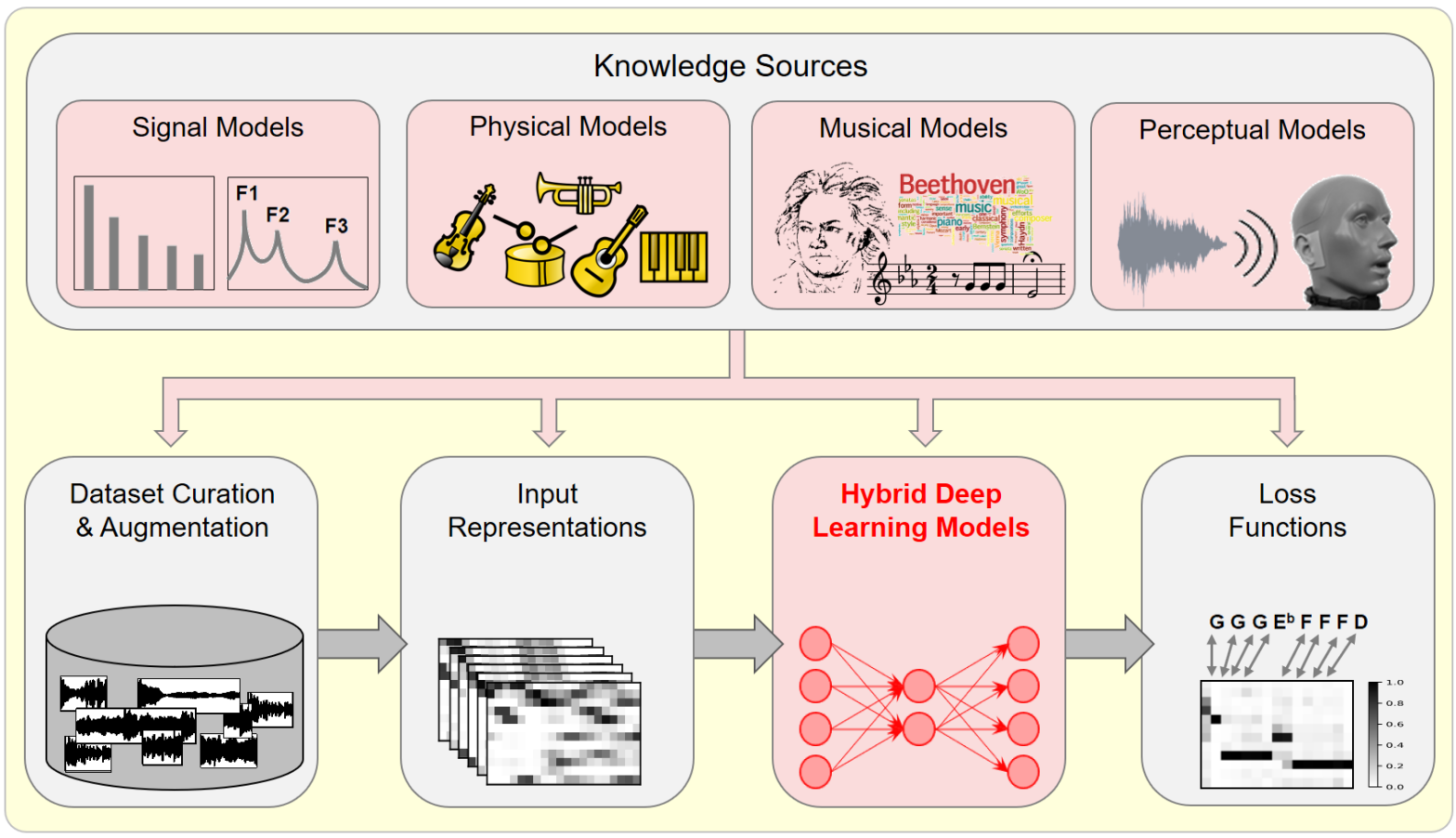
In this article, we investigate the notion of model-based deep learning in the realm of music information research (MIR). Loosely speaking, we refer to the term model-based deep learning for approaches that combine traditional knowledge-based methods with data-driven techniques, especially those based on deep learning, within a diff erentiable computing framework. In music, prior knowledge for instance related to sound production, music perception or music composition theory can be incorporated into the design of neural networks and associated loss functions. We outline three specific scenarios to illustrate the application of model-based deep learning in MIR, demonstrating the implementation of such concepts and their potential.
Tag: AI
Detection of Deepfake Environmental Audio @ EUSIPCO
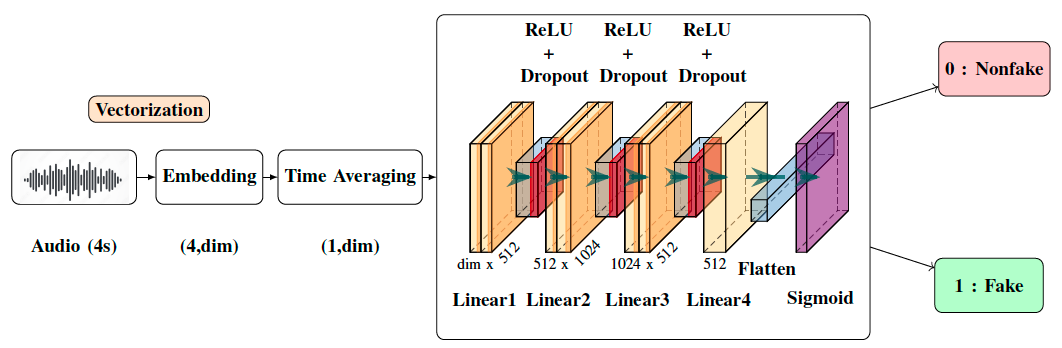
With the ever-rising quality of deep generative models, it is increasingly important to be able to discern whether the audio data at hand have been recorded or synthesized. Although the detection of fake speech signals has been studied extensively, this is not the case for the detection of fake environmental audio. We propose a simple and efficient pipeline for detecting fake environmental sounds based on the CLAP audio embedding. We evaluate this detector using audio data from the 2023 DCASE challenge task on Foley sound synthesis.
Our experiments show that fake sounds generated by 44 state-of-the-art synthesizers can be detected on average with 98\% accuracy. We show that using an audio embedding trained specifically on environmental audio is beneficial over a standard VGGish one as it provides a 10% increase in detection performance. The sounds misclassified by the detector were tested in an experiment on human listeners who showed modest accuracy with nonfake sounds, suggesting there may be unexploited audible features.
Correlation of Fréchet Audio Distance With Human Perception of Environmental Audio Is Embedding Dependent @ EUSIPCO
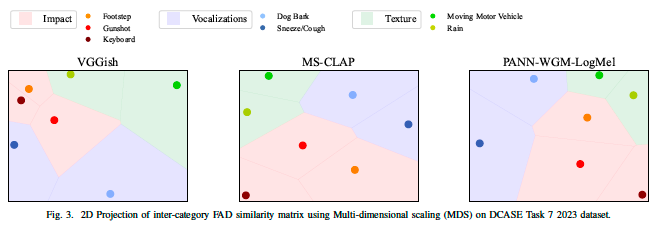
This paper explores whether considering alternative domain-specific embeddings to calculate the Fréchet Audio Distance (FAD) metric can help the FAD to correlate better with perceptual ratings of environmental sounds. We used embeddings from VGGish, PANNs, MS-CLAP, L-CLAP, and MERT, which are tailored for either music or environmental sound evaluation. The FAD scores were calculated for sounds from the DCASE 2023 Task 7 dataset. Using perceptual data from the same task, we find that PANNs-WGM-LogMel produces the best correlation between FAD scores and perceptual ratings of both audio quality and perceived fit with a Spearman correlation higher than 0.5. We also find that music-specific embeddings resulted in significantly lower results. Interestingly, VGGish, the embedding used for the original Fréchet calculation, yielded a correlation below 0.1. These results underscore the critical importance of the choice of embedding for the FAD metric design.
PhD offer: Machine learning on solar-powered environmental sensors

Many biological and geophysical phenomena follow a near-periodic day-night cycle, known as circadian rhythm. When designing AI-enabled autonomous sensors for environmental modeling, this circadian rhythm poses both a challenge and an opportunity.
PhD offer: Developmental robotics of birdsong

The Neurocybernetic team of ETIS Lab (CNRS, CY Cergy-Paris University, ENSEA) is seeking applicants for a fully funded PhD place providing an exciting opportunity to pursue a postgraduate research in the fields of bio/neuro-inspired robotics, ethology, neuroscience.Webpage: https://www.etis-lab.fr/neuro/ This PhD is funded by the French ANR, under the 4 years’ project “Nirvana” on sensorimotor integration of… Continue reading PhD offer: Developmental robotics of birdsong
Kymatio notebooks @ ISMIR 2023

On November 5th, 2023, we hosted a tutorial on Kymatio, entitled “Deep Learning meets Wavelet Theory for Music Signal Processing”, as part of the International Society for Music Information Retrieval (ISMIR) conference in Milan, Italy.
The Jupyter notebooks below were authored by Chris Mitcheltree and Cyrus Vahidi from Queen Mary University of London.
Mathieu, Vincent, and Modan present at DCASE

Our group has presented two challenge tasks and two papers at the international workshop on Detection and Classification of Acoustic Scenes and Events (DCASE), held in Tampere (Finland) in September 2023.
Apprentissage de variété riemannienne pour l’analyse-synthèse de signaux non stationnaires @ GRETSI
Foley sound synthesis at the DCASE 2023 challenge

The addition of Foley sound effects during post-production is a common technique used to enhance the perceived acoustic properties of multimedia content. Traditionally, Foley sound has been produced by human Foley artists, which involves manual recording and mixing of sound. However, recent advances in sound synthesis and generative models have generated interest in machine-assisted or… Continue reading Foley sound synthesis at the DCASE 2023 challenge
ReNAR: Reducing Noise with Augmented Reality
Noise pollution has a significant impact on quality of life. In the office, noise exposure creates stress that leads to reduced performance, provokes annoyance responses and changes in social behaviour. Headphones with excellent noise-cancelling processors can now be acquired in order to protect oneself from the noise exposure. While these techniques have reached a high… Continue reading ReNAR: Reducing Noise with Augmented Reality