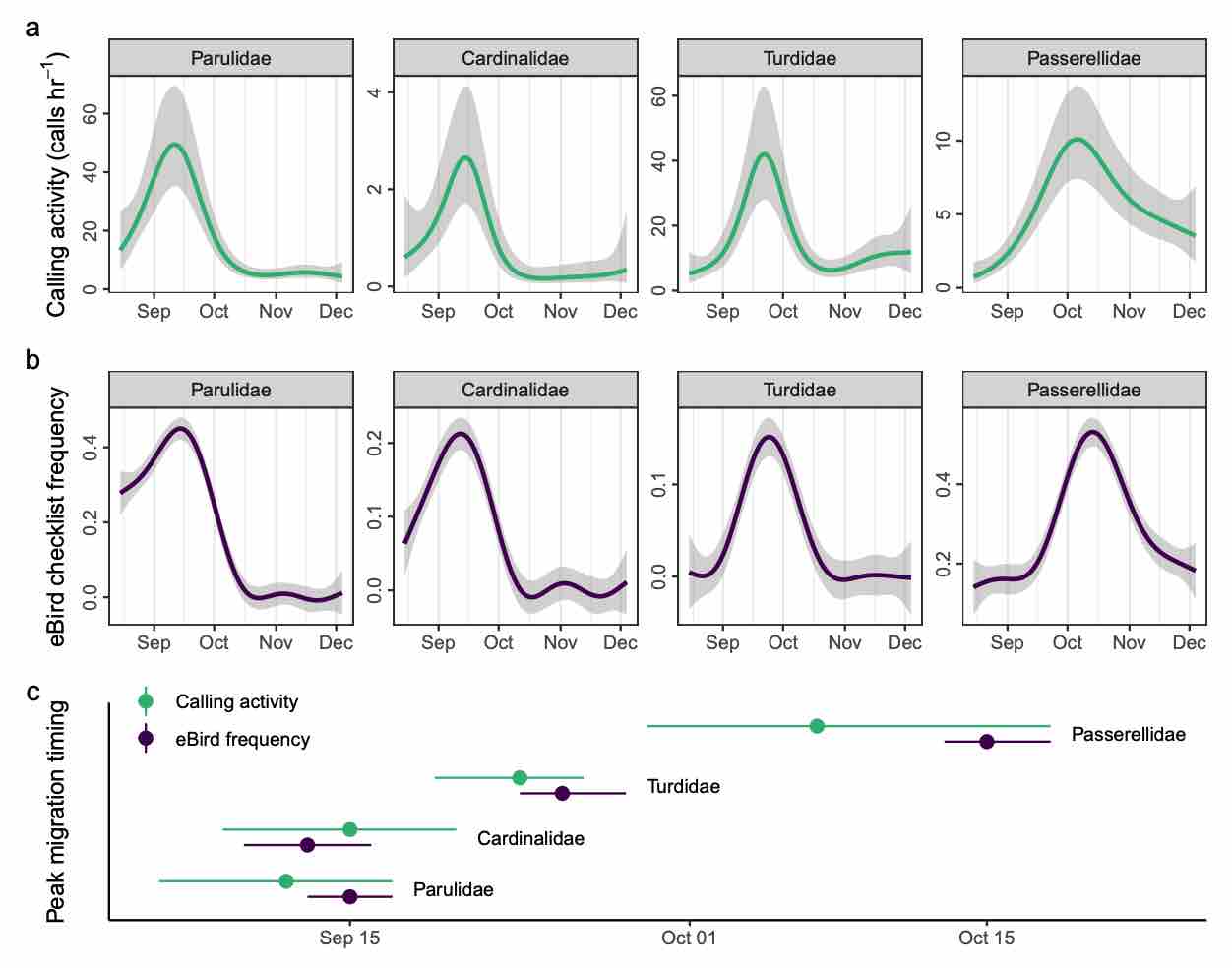
Monitoring small, mobile organisms is crucial for science and conservation, but is technically challenging. Migratory birds are prime examples, often undertaking nocturnal movements of thousands of kilometres over inaccessible and inhospitable geography. Acoustic technology could facilitate widespread monitoring of nocturnal bird migration with minimal human effort. Acoustics complements existing monitoring methods by providing information about individual behaviour and species identities, something generally not possible with tools such as radar. However, the need for expert humans to review audio and identify vocalizations is a challenge to application and development of acoustic technologies. Here, we describe an automated acoustic monitoring pipeline that combines acoustic sensors with machine listening software (BirdVoxDetect). We monitor 4 months of autumn migration in the northeastern United States with five acoustic sensors, extracting nightly estimates of nocturnal calling activity of 14 migratory species with distinctive flight calls. We examine the ability of acoustics to inform two important facets of bird migration: (1) the quantity of migrating birds aloft and (2) the migration timing of individual species. We validate these data with contemporaneous observations from Doppler radars and a large community of citizen scientists, from which we derive independent measures of migration passage and timing. Together, acoustic and weather data produced accurate estimates of the number of actively migrating birds detected with radar. A model combining acoustic data, weather and seasonal timing explained 75% of variation in radar-derived migration intensity. This model outperformed models that lacked acoustic data. Including acoustics in the model decreased prediction error by 33%. A model with only acoustic information outperformed a model comprising weather and date (57% vs. 48% variation explained, respectively). Acoustics also successfully measured migration phenology: species-specific timing estimated by acoustic sensors explained 71% of variation in timing derived from citizen science observations. Our results demonstrate that cost-effective acoustic sensors can monitor bird migration at species resolution at the landscape scale and should be an integral part of management toolkits. Acoustic monitoring presents distinct advantages over radar and human observation, especially in inaccessible and inhospitable locations, and requires significantly less expense. Managers should consider using acoustic tools for monitoring avian movements and identifying and understanding dangerous situations for birds. These recommendations apply to a variety of conservation and policy applications, including mitigating the impacts of light pollution, siting energy infrastructure (e.g. wind turbines) and reducing collisions with structures and aircraft.