

“Less is more”, once the foundational motto of minimalist art, is making its way into artificial intelligence. After a maximalist decade of larger computers training larger neural networks on larger datasets (2012-2022), a countertrend arises. What if human-level performance could be achieved with less computing, less memory, and less supervision? In deep learning, the research… Continue reading MuReNN: Multi-Resolution Neural Networks
Tag: AI
Explainable audio classification of playing techniques with layerwise relevance propagation @ IEEE ICASSP
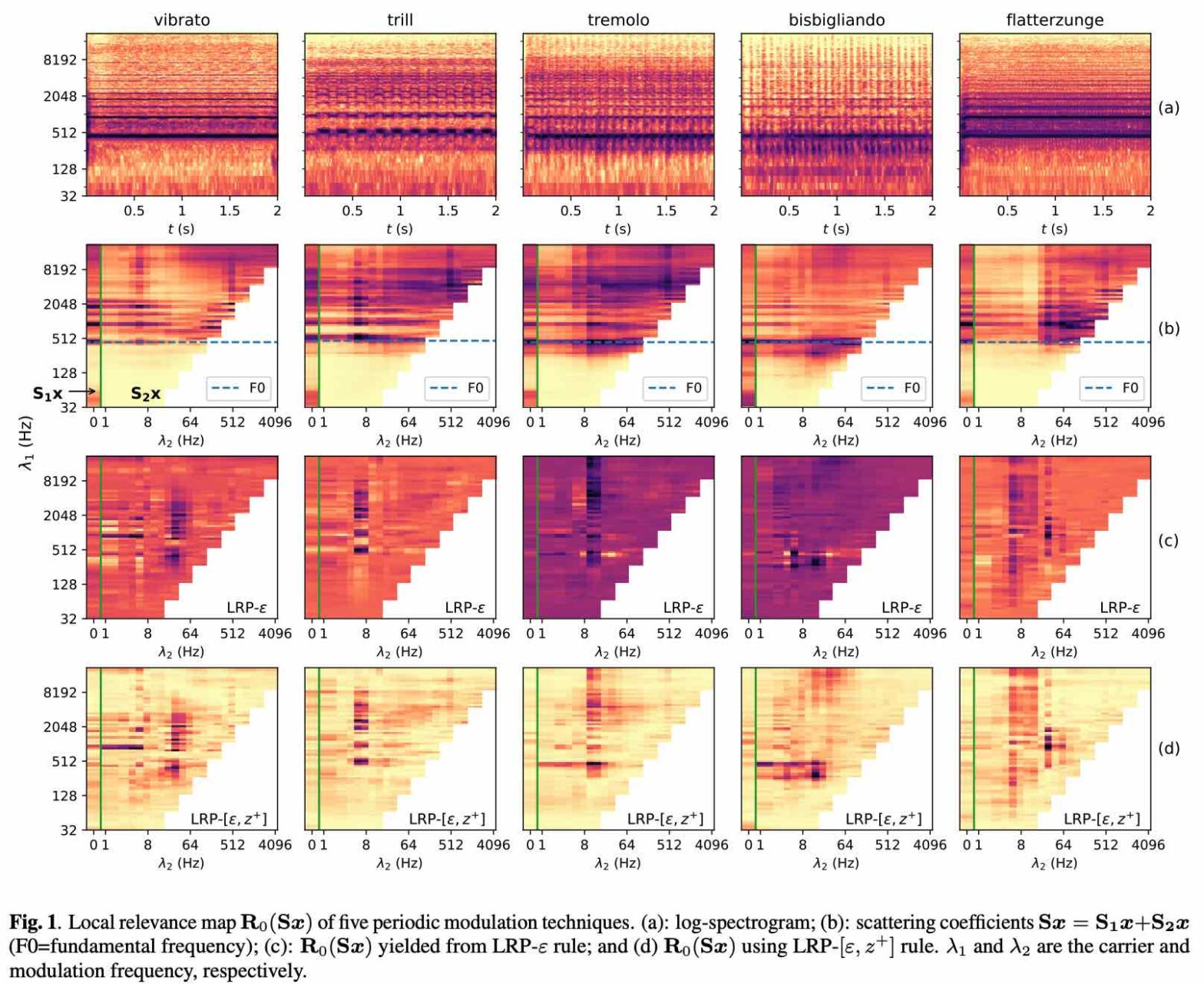
Deep convolutional networks (convnets) in the time-frequency domain can learn an accurate and fine-grained categorization of sounds. For example, in the context of music signal analysis, this categorization may correspond to a taxonomy of playing techniques: vibrato, tremolo, trill, and so forth. However, convnets lack an explicit connection with the neurophysiological underpinnings of musical timbre perception. In this article, we propose a data-driven approach to explain audio classification in terms of physical attributes in sound production. We borrow from current literature in “explainable AI” (XAI) to study the predictions of a convnet which achieves an almost perfect score on a challenging task: i.e., the classification of five comparable real-world playing techniques from 30 instruments spanning seven octaves. Mapping the signal into the carrier-modulation domain using scattering transform, we decompose the networks’ predictions over this domain with layer-wise relevance propagation. We find that regions highly-relevant to the predictions localized around the physical attributes with which the playing techniques are performed.
Perceptual–Physical–Sound Matching @ IEEE ICASSP
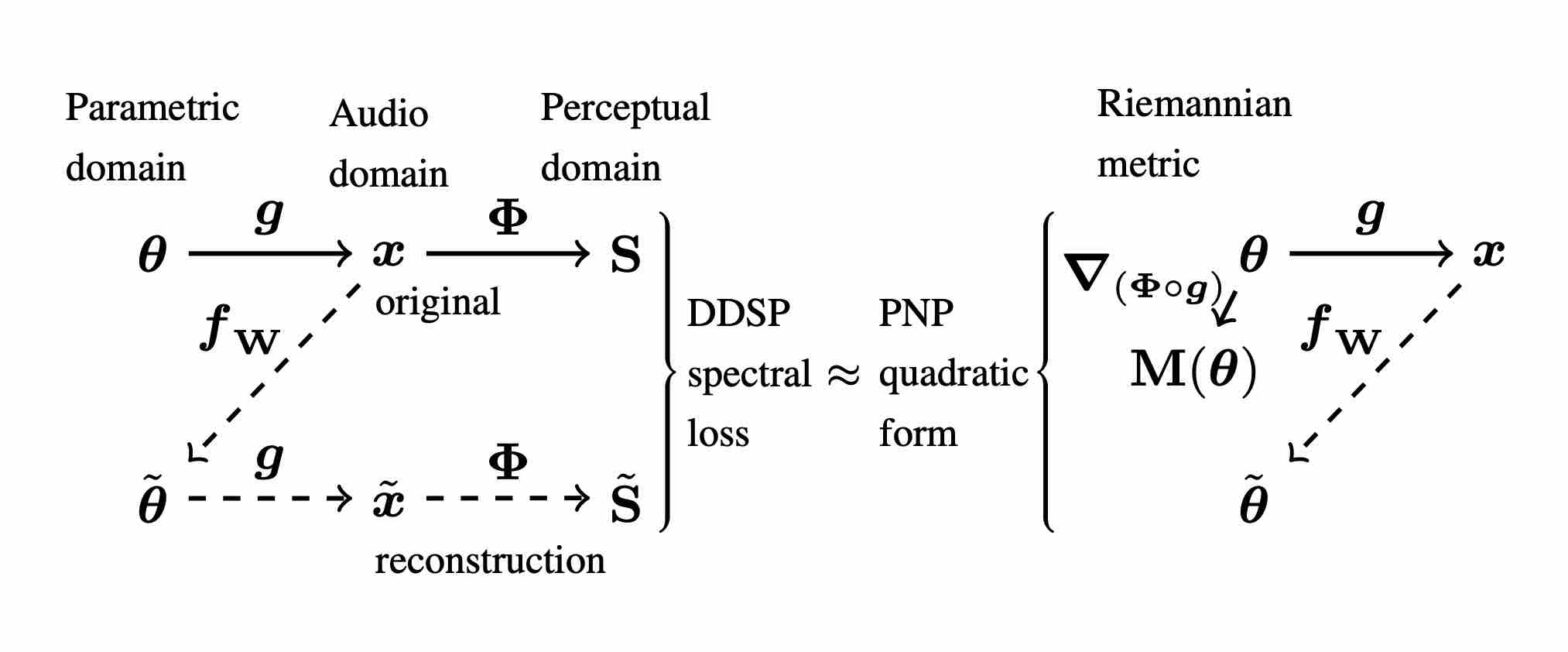
Sound matching algorithms seek to approximate a target waveform by parametric audio synthesis. Deep neural networks have achieved promising results in matching sustained harmonic tones. However, the task is more challenging when targets are nonstationary and inharmonic, e.g., percussion. We attribute this problem to the inadequacy of loss function. On one hand, mean square error in the parametric domain, known as “P-loss”, is simple and fast but fails to accommodate the differing perceptual significance of each parameter. On the other hand, mean square error in the spectrotemporal domain, known as “spectral loss”, is perceptually motivated and serves in differentiable digital signal processing (DDSP). Yet, spectral loss is a poor predictor of pitch intervals and its gradient may be computationally expensive; hence a slow convergence. Against this conundrum, we present Perceptual-Neural-Physical loss (PNP). PNP is the optimal quadratic approximation of spectral loss while being as fast as P-loss during training. We instantiate PNP with physical modeling synthesis as decoder and joint time-frequency scattering transform (JTFS) as spectral representation. We demonstrate its potential on matching synthetic drum sounds in comparison with other loss functions.