

Category: Publications
Foley sound synthesis at the DCASE 2023 challenge

The addition of Foley sound effects during post-production is a common technique used to enhance the perceived acoustic properties of multimedia content. Traditionally, Foley sound has been produced by human Foley artists, which involves manual recording and mixing of sound. However, recent advances in sound synthesis and generative models have generated interest in machine-assisted or… Continue reading Foley sound synthesis at the DCASE 2023 challenge
Automated acoustic monitoring captures timing and intensity of bird migration @ J. Applied Ecology
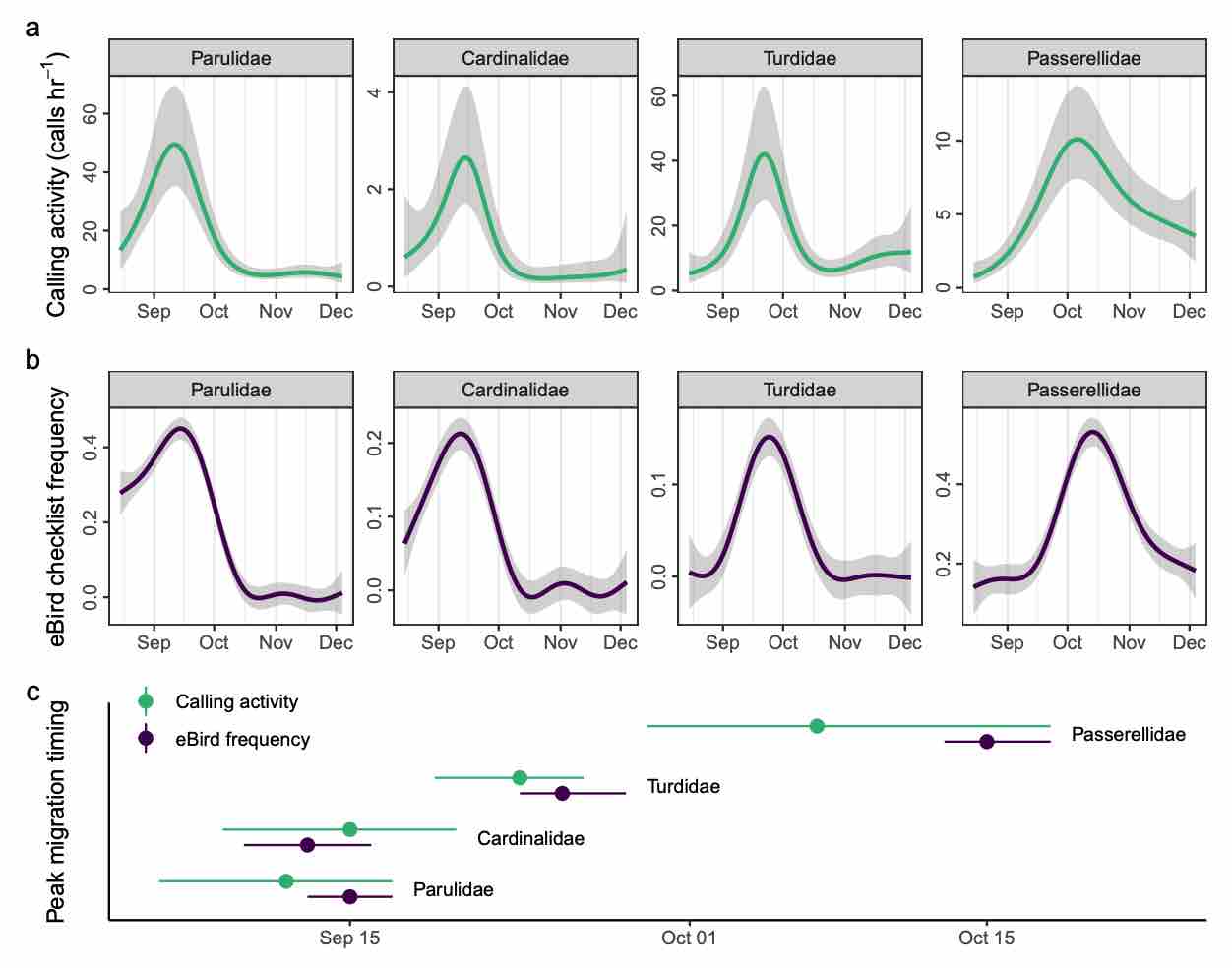
Monitoring small, mobile organisms is crucial for science and conservation, but is technically challenging. Migratory birds are prime examples, often undertaking nocturnal movements of thousands of kilometres over inaccessible and inhospitable geography. Acoustic technology could facilitate widespread monitoring of nocturnal bird migration with minimal human effort. Acoustics complements existing monitoring methods by providing information about individual behaviour and species identities, something generally not possible with tools such as radar. However, the need for expert humans to review audio and identify vocalizations is a challenge to application and development of acoustic technologies. Here, we describe an automated acoustic monitoring pipeline that combines acoustic sensors with machine listening software (BirdVoxDetect). We monitor 4 months of autumn migration in the northeastern United States with five acoustic sensors, extracting nightly estimates of nocturnal calling activity of 14 migratory species with distinctive flight calls. We examine the ability of acoustics to inform two important facets of bird migration: (1) the quantity of migrating birds aloft and (2) the migration timing of individual species. We validate these data with contemporaneous observations from Doppler radars and a large community of citizen scientists, from which we derive independent measures of migration passage and timing. Together, acoustic and weather data produced accurate estimates of the number of actively migrating birds detected with radar. A model combining acoustic data, weather and seasonal timing explained 75% of variation in radar-derived migration intensity. This model outperformed models that lacked acoustic data. Including acoustics in the model decreased prediction error by 33%. A model with only acoustic information outperformed a model comprising weather and date (57% vs. 48% variation explained, respectively). Acoustics also successfully measured migration phenology: species-specific timing estimated by acoustic sensors explained 71% of variation in timing derived from citizen science observations. Our results demonstrate that cost-effective acoustic sensors can monitor bird migration at species resolution at the landscape scale and should be an integral part of management toolkits. Acoustic monitoring presents distinct advantages over radar and human observation, especially in inaccessible and inhospitable locations, and requires significantly less expense. Managers should consider using acoustic tools for monitoring avian movements and identifying and understanding dangerous situations for birds. These recommendations apply to a variety of conservation and policy applications, including mitigating the impacts of light pollution, siting energy infrastructure (e.g. wind turbines) and reducing collisions with structures and aircraft.
Spectral trancoder: using pretrained urban sound classifiers on undersampled spectral representations @ DCASE
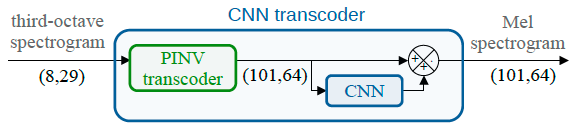
Slow or fast third-octave bands representations (with a frame resp. every 1-s and 125-ms) have been a de facto standard for urban acoustics, used for example in long-term monitoring applications. It has the advantages of requiring few storage capabilities and of preserving privacy. As most audio classification algorithms take Mel spectral representations with very fast… Continue reading Spectral trancoder: using pretrained urban sound classifiers on undersampled spectral representations @ DCASE
Perceptual musical similarity metric learning with graph neural networks @ IEEE WASPAA
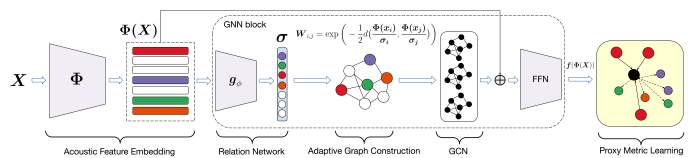
Sound retrieval for assisted music composition depends on evaluating similarity between musical instrument sounds, which is partly influenced by playing techniques. Previous methods utilizing Euclidean nearest neighbours over acoustic features show some limitations in retrieving sounds sharing equivalent timbral properties, but potentially generated using a different instrument, playing technique, pitch or dynamic. In this paper,… Continue reading Perceptual musical similarity metric learning with graph neural networks @ IEEE WASPAA
Zero-Note Samba: Self-supervised beat tracking @ IEEE TASLP
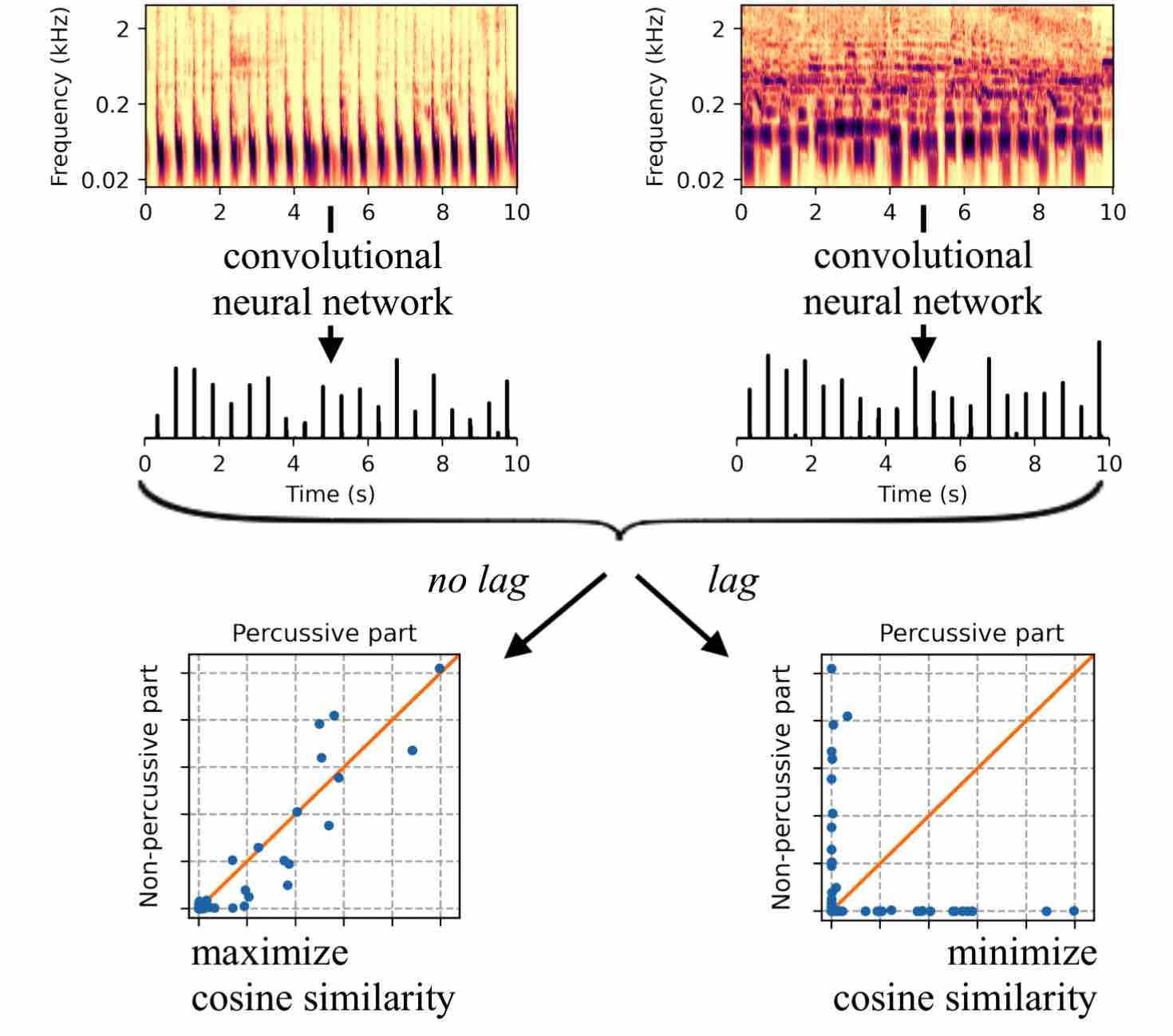
Supervised machine learning for music information retrieval requires a large annotated training set, and thus a high cognitive workload. To circumvent this problem, we propose to train deep neural networks to perceive beats in musical recordings despite having little or no access to human annotations. The key idea, which we name “Zero-Note Samba” (ZeroNS), is to train two fully convolutional networks in parallel: the first analyzes the percussive part of a musical piece whilst the second analyzes its non-percussive part. These networks learn a self-supervised pretext task of synchrony prediction (sync-pred), which simulates the ability of musicians to groove together when playing in the same band. Sync-pred encourages the two networks to return similar outputs if the underlying musical parts are synchronized, yet dissimilar outputs if the parts are out of sync. In practice, we obtain the instrumental parts from commercial recordings via an off-the-shelf source separation system: Spleeter. After self-supervised learning with sync-pred, ZeroNS produces a sparse output that resembles a beat detection function. When used in conjunction with a dynamic Bayesian network, ZeroNS surpasses the state of the art in unsupervised beat tracking. Furthermore, fine-tuning ZeroNS to a small set of labeled data (of the order of one to ten songs) matches the performance of a fully supervised network on 96 songs. Lastly, we show that pre-training a supervised model with sync-pred mitigates dataset bias and thus improves cross-dataset generalization, at no extra annotation cost.
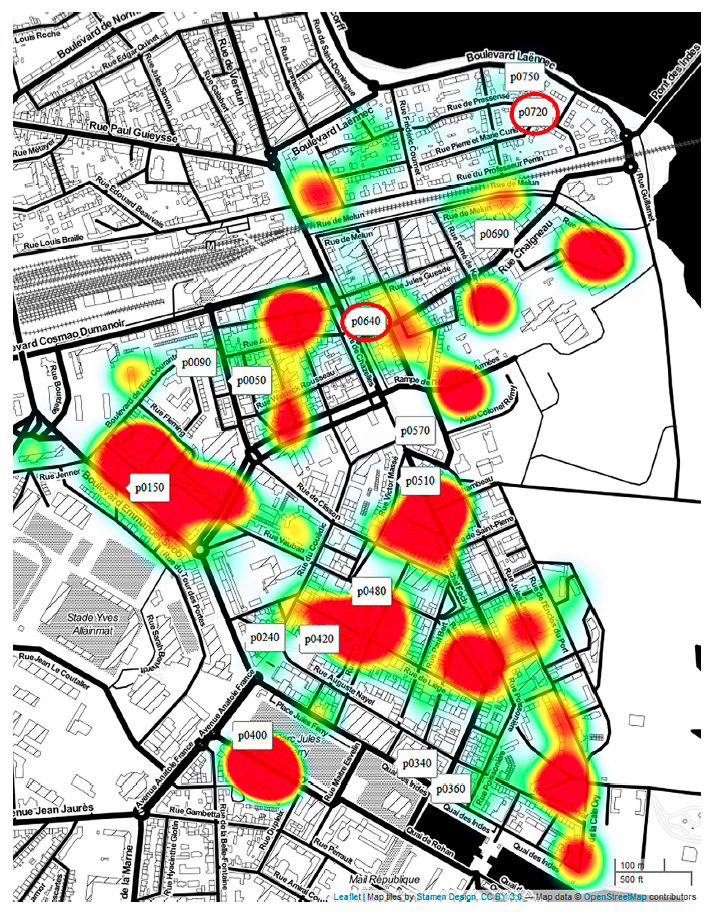
Multidimensional analyses of the noise impacts of COVID-19 lockdown @ JASA
An interactive bi-objective optimisation process to guide the design of electric vehicle warning sounds @ Design Science
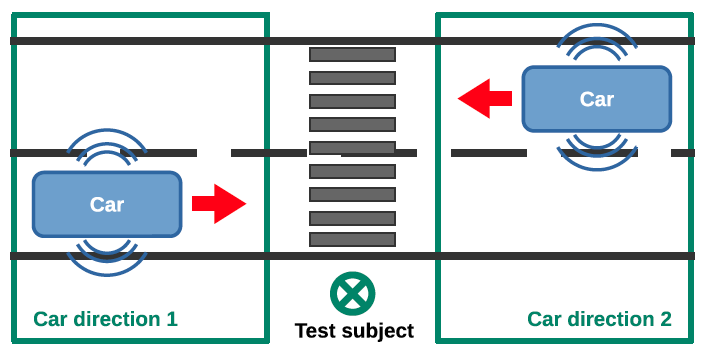
Abstract Electric vehicles (EVs) are very quiet at low speed, which can be hazardous for pedestrians, especially visually impaired people. It is now mandatory (since mid-2019 in Europe) to add external warning sounds, but poor sound design can lead to noise pollution, and consequently annoyance. Moreover, it is possible that EVs are not sufficiently detectable… Continue reading An interactive bi-objective optimisation process to guide the design of electric vehicle warning sounds @ Design Science
Mesostructures: Beyond spectrogram loss in differentiable time-frequency analysis @ JAES
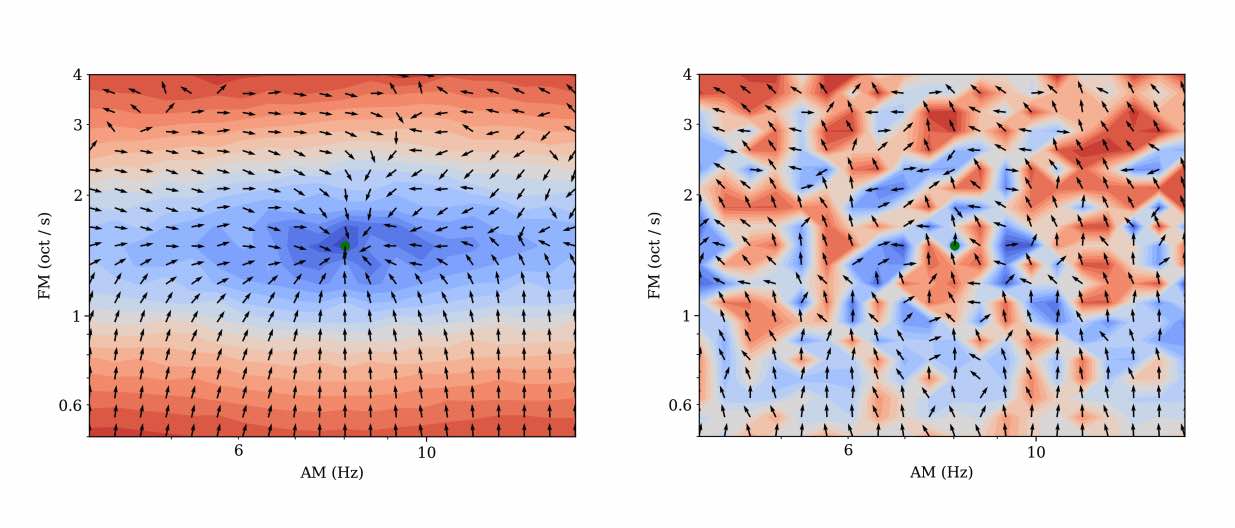
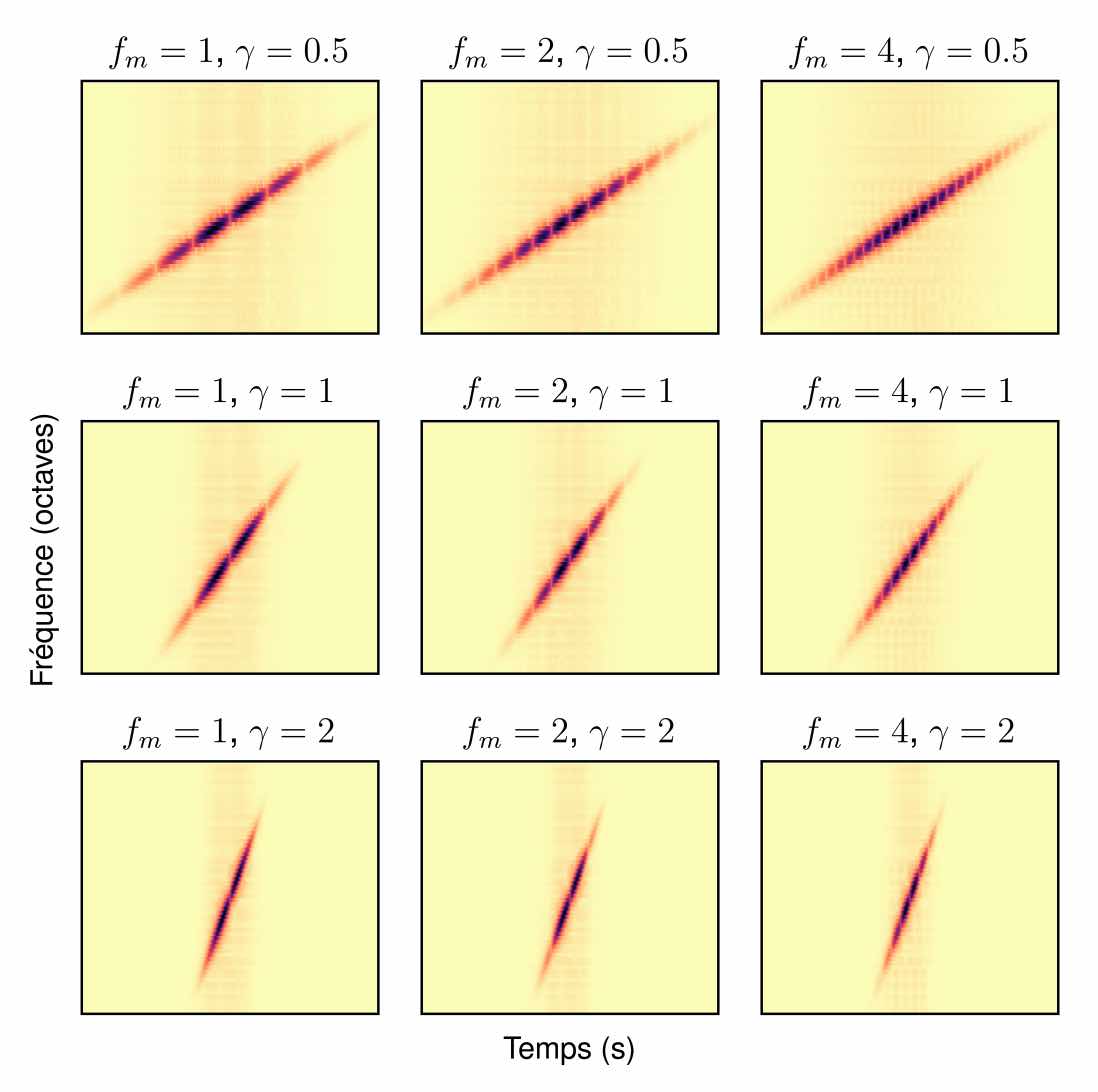
Computer musicians refer to mesostructures as the intermediate levels of articulation between the microstructure of waveshapes and the macrostructure of musical forms. Examples of mesostructures include melody, arpeggios, syncopation, polyphonic grouping, and textural contrast. Despite their central role in musical expression, they have received limited attention in recent applications of deep learning to the analysis and synthesis of musical audio. Currently, autoencoders and neural audio synthesizers are only trained and evaluated at the scale of microstructure: i.e., local amplitude variations up to 100 milliseconds or so. In this paper, we formulate and address the problem of mesostructural audio modeling via a composition of a differentiable arpeggiator and time-frequency scattering. We empirically demonstrate that time-frequency scattering serves as a differentiable model of similarity between synthesis parameters that govern mesostructure. By exposing the sensitivity of short-time spectral distances to time alignment, we motivate the need for a time-invariant and multiscale differentiable time-frequency model of similarity at the level of both local spectra and spectrotemporal modulations.
Fitting Auditory Filterbanks with MuReNN @ IEEE WASPAA
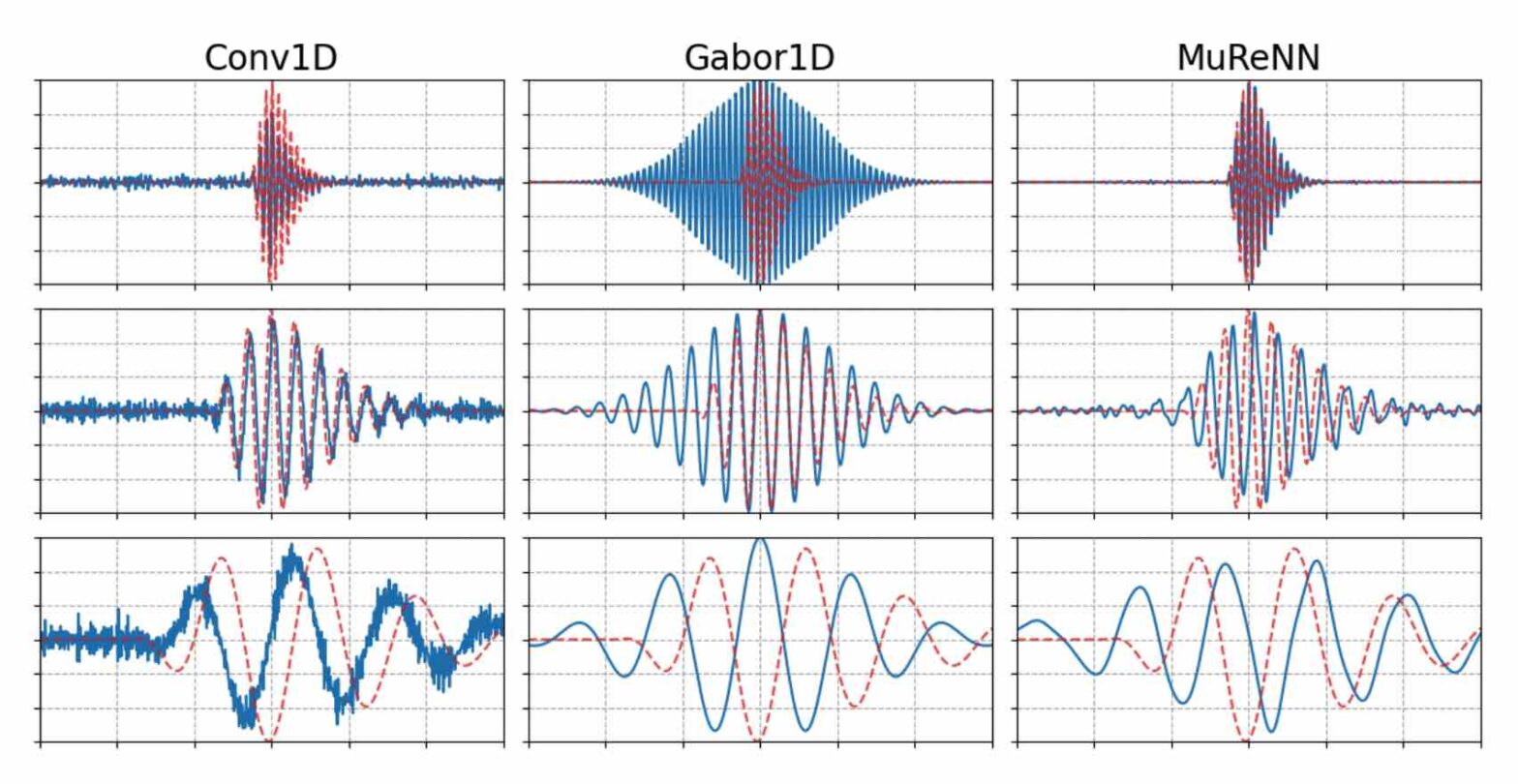
Waveform-based deep learning faces a dilemma between nonparametric and parametric approaches. On one hand, convolutional neural networks (convnets) may approximate any linear time-invariant system; yet, in practice, their frequency responses become more irregular as their receptive fields grow. On the other hand, a parametric model such as LEAF is guaranteed to yield Gabor filters, hence an optimal time-frequency localization; yet, this strong inductive bias comes at the detriment of representational capacity. In this paper, we aim to overcome this dilemma by introducing a neural audio model, named multiresolution neural network (MuReNN). The key idea behind MuReNN is to train separate convolutional operators over the octave subbands of a discrete wavelet transform (DWT). Since the scale of DWT atoms grows exponentially between octaves, the receptive fields of the subsequent learnable convolutions in MuReNN are dilated accordingly. For a given real-world dataset, we fit the magnitude response of MuReNN to that of a wellestablished auditory filterbank: Gammatone for speech, CQT for music, and third-octave for urban sounds, respectively. This is a form of knowledge distillation (KD), in which the filterbank “teacher” is engineered by domain knowledge while the neural network “student” is optimized from data. We compare MuReNN to the state of the art in terms of goodness of fit after KD on a hold-out set and in terms of Heisenberg time-frequency localization. Compared to convnets and Gabor convolutions, we find that MuReNN reaches state-of-the-art performance on all three optimization problems.