

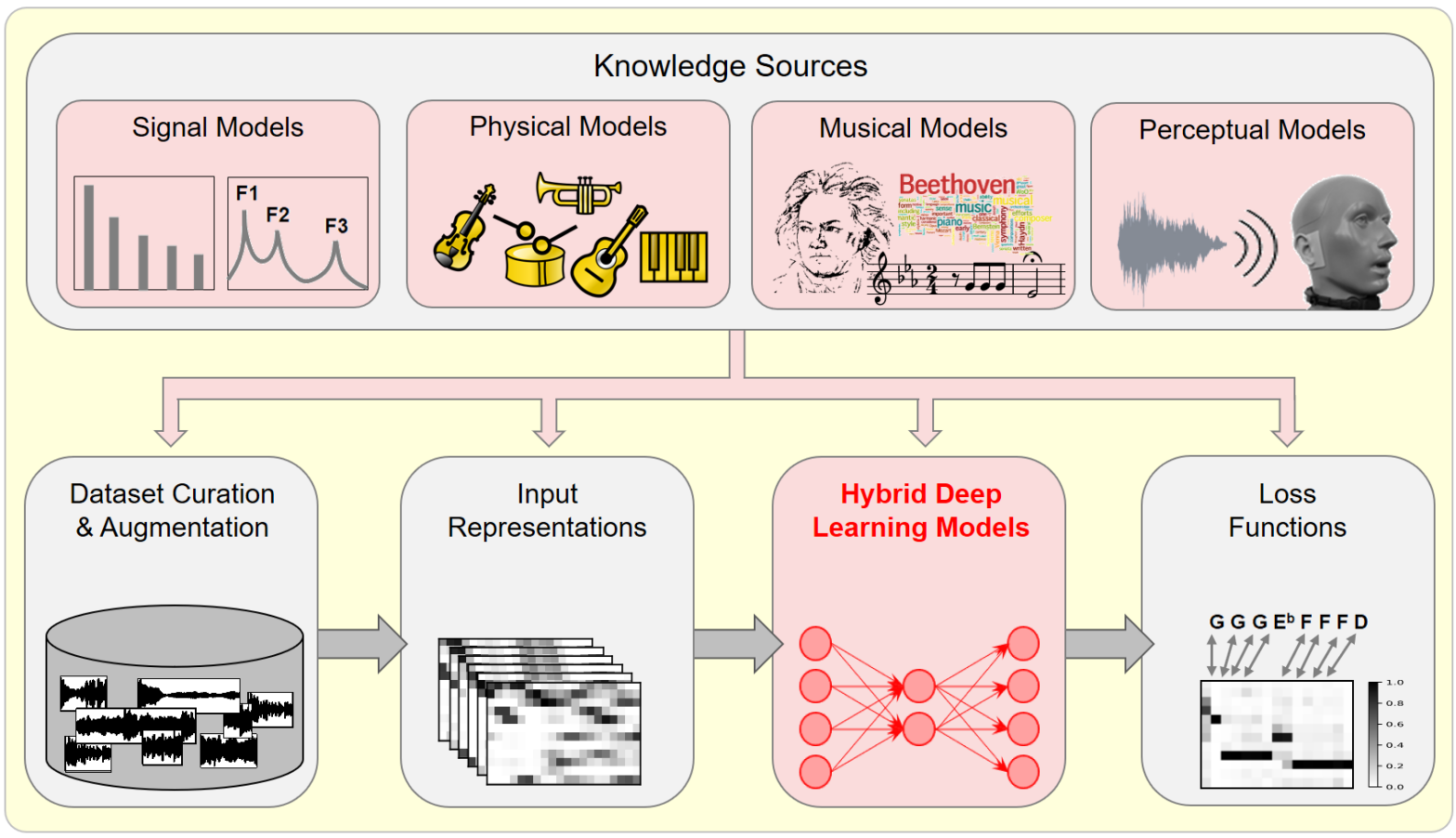
In this article, we investigate the notion of model-based deep learning in the realm of music information research (MIR). Loosely speaking, we refer to the term model-based deep learning for approaches that combine traditional knowledge-based methods with data-driven techniques, especially those based on deep learning, within a diff erentiable computing framework. In music, prior knowledge for instance related to sound production, music perception or music composition theory can be incorporated into the design of neural networks and associated loss functions. We outline three specific scenarios to illustrate the application of model-based deep learning in MIR, demonstrating the implementation of such concepts and their potential.
Category: Publications
Detection of Deepfake Environmental Audio @ EUSIPCO
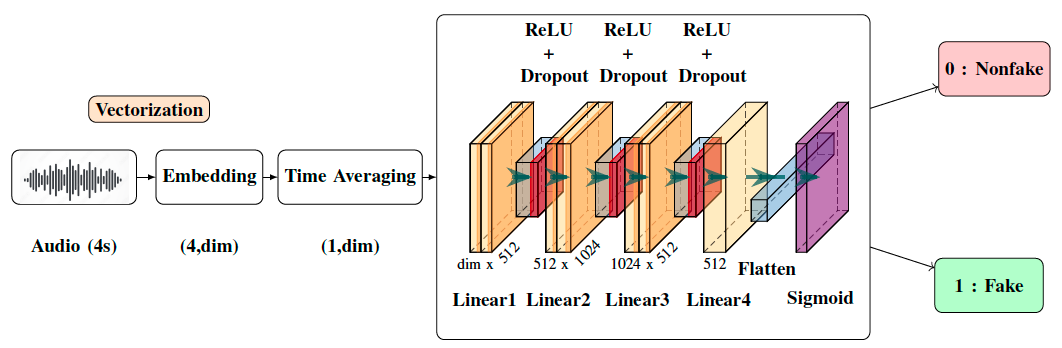
With the ever-rising quality of deep generative models, it is increasingly important to be able to discern whether the audio data at hand have been recorded or synthesized. Although the detection of fake speech signals has been studied extensively, this is not the case for the detection of fake environmental audio. We propose a simple and efficient pipeline for detecting fake environmental sounds based on the CLAP audio embedding. We evaluate this detector using audio data from the 2023 DCASE challenge task on Foley sound synthesis.
Our experiments show that fake sounds generated by 44 state-of-the-art synthesizers can be detected on average with 98\% accuracy. We show that using an audio embedding trained specifically on environmental audio is beneficial over a standard VGGish one as it provides a 10% increase in detection performance. The sounds misclassified by the detector were tested in an experiment on human listeners who showed modest accuracy with nonfake sounds, suggesting there may be unexploited audible features.
Correlation of Fréchet Audio Distance With Human Perception of Environmental Audio Is Embedding Dependent @ EUSIPCO
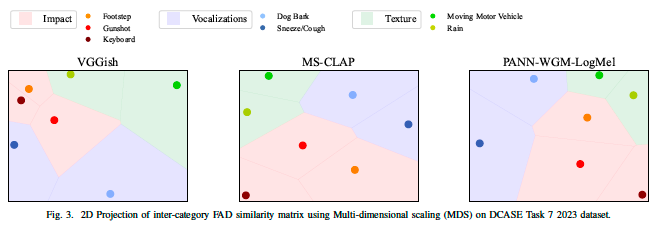
This paper explores whether considering alternative domain-specific embeddings to calculate the Fréchet Audio Distance (FAD) metric can help the FAD to correlate better with perceptual ratings of environmental sounds. We used embeddings from VGGish, PANNs, MS-CLAP, L-CLAP, and MERT, which are tailored for either music or environmental sound evaluation. The FAD scores were calculated for sounds from the DCASE 2023 Task 7 dataset. Using perceptual data from the same task, we find that PANNs-WGM-LogMel produces the best correlation between FAD scores and perceptual ratings of both audio quality and perceived fit with a Spearman correlation higher than 0.5. We also find that music-specific embeddings resulted in significantly lower results. Interestingly, VGGish, the embedding used for the original Fréchet calculation, yielded a correlation below 0.1. These results underscore the critical importance of the choice of embedding for the FAD metric design.
Towards multisensory control of physical modeling synthesis @ Inter-Noise

Physical models of musical instruments offer an interesting tradeoff between computational efficiency and perceptual fidelity. Yet, they depend on a multidimensional space of user-defined parameters whose exploration by trial and error is impractical. Our article addresses this issue by combining two ideas: query by example and gestural control. On one hand, we train a deep… Continue reading Towards multisensory control of physical modeling synthesis @ Inter-Noise
Structure Versus Randomness in Computer Music and the Scientific Legacy of Jean-Claude Risset @ JIM

According to Jean-Claude Risset (1938–2016), “art and science bring about complementary kinds of knowledge”. In 1969, he presented his piece Mutations as “[attempting] to explore […] some of the possibilities offered by the computer to compose at the very level of sound—to compose sound itself, so to speak.” In this article, I propose to take the same motto as a starting point, yet while adopting a mathematical and technological outlook, more so than a musicological one.
Instabilities in Convnets for Raw Audio @ IEEE SPL
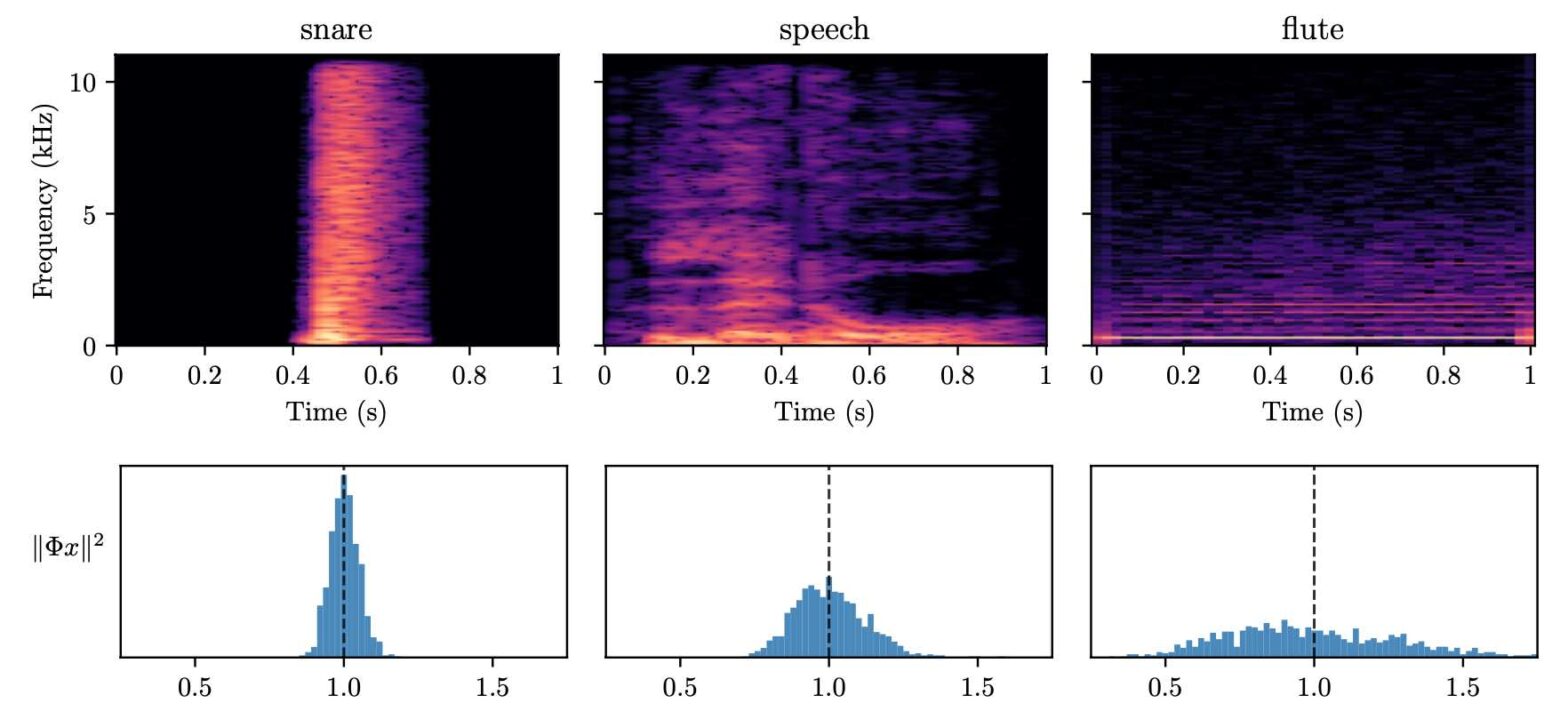
What makes waveform-based deep learning so hard? Despite numerous attempts at training convolutional neural networks (convnets) for filterbank design, they often fail to outperform hand-crafted baselines. These baselines are linear time-invariant systems: as such, they can be approximated by convnets with wide receptive fields. Yet, in practice, gradient-based optimization leads to suboptimal approximations. In our… Continue reading Instabilities in Convnets for Raw Audio @ IEEE SPL
Towards constructing a historically grounded gesture-timbre space of Guqin playing techniques @ Timbre

Guqin is an ancient Chinese zither instrument known for its timbral variability and the vital role timbre, as opposed to melody or rhythm, played in its classical compositions. Numerous ancient texts dating back to the 1500s provided gestural guidelines of defined Guqin playing techniques and recommendations on timbre aesthetics. It’s also suggested in these texts that small deviations in gestures have significant impact on resulting timbres. Nevertheless, traditionally and even today, Guqin pedagogies are largely metaphoric, mind instead of body, and include limited elaboration on recommended gestures. To digitize and concretize the sonic implications in Guqin gesture-timbre writings, and variegate within the oversimplified vocabulary of playing techniques, this study aims to design and record a dataset of isolated, short, representative Guqin sounds labeled by gestural data. The sounds in question are curated by extracting ancient text, where emphasis on gesture-induced timbral difference is mentioned. We decompose the notion of gesture into nine degrees of freedom for both hands, including left/right hand position, fingers used, point of contact, left/right hand temporal coordination, etc. We define a ladder of gestural data at various levels, ranging from discrete labels of playing techniques, the aforementioned degrees of freedom to continuous signals acquired by high-speed camera with automatic hand-tracking system. We analyze in time-frequency domain timbres resulting from conventional playing gestures and their systematically “perturbed” versions. We investigate the correlation between timbres and their underlying gestures, via methods derived from multidimensional scaling.
Efficient Evaluation Algorithms for Sound Event Detection @ DCASE
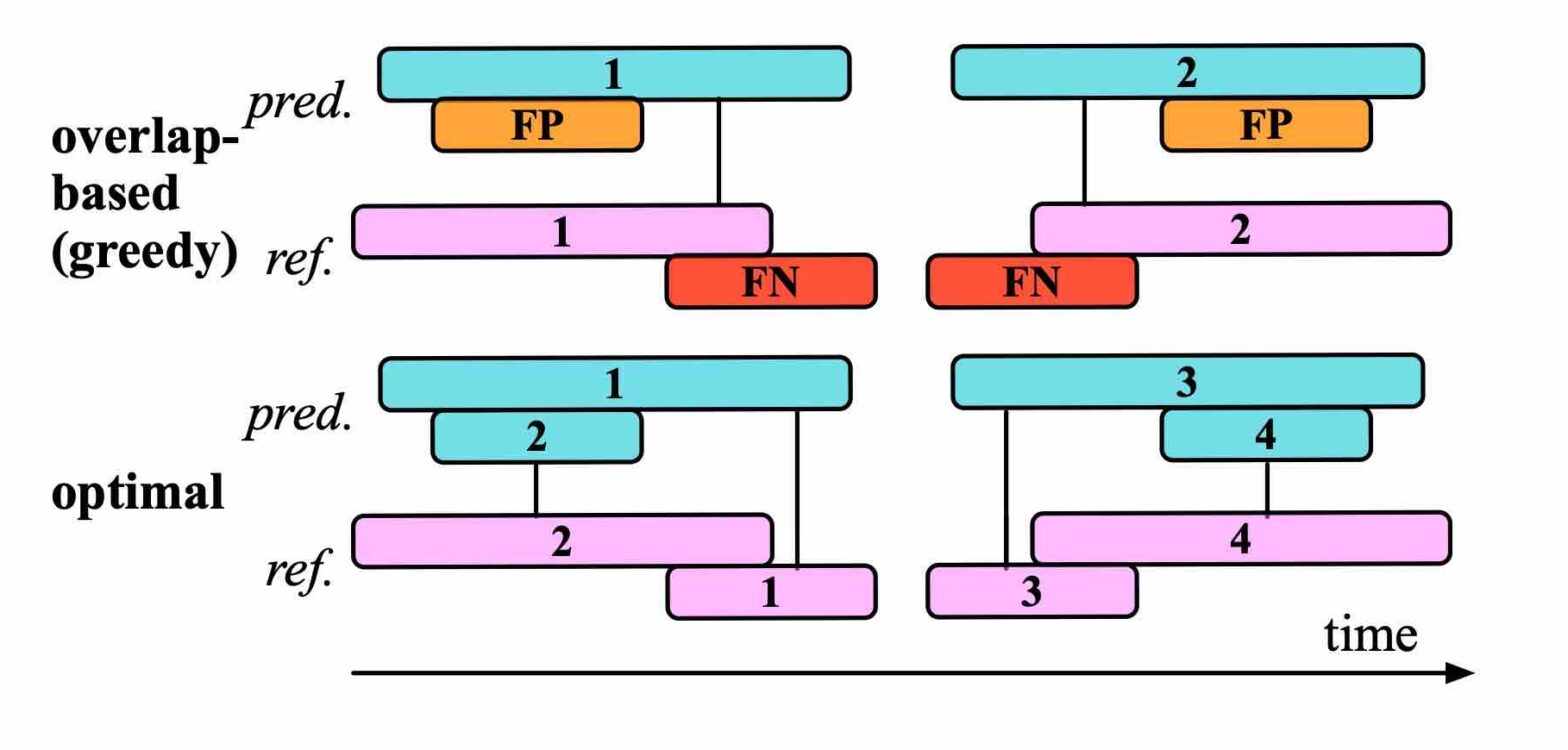
Our article presents an algorithm for pairwise intersection of intervals by performing binary search within sorted onset and offset times. Computational benchmarks on the BirdVox-full-night dataset confirms that our algorithm is significantly faster than exhaustive search. Moreover, we explain how to use this list of intersecting prediction-reference pairs for the purpose of SED evaluation.
Apprentissage de variété riemannienne pour l’analyse-synthèse de signaux non stationnaires @ GRETSI
Foley sound synthesis at the DCASE 2023 challenge

The addition of Foley sound effects during post-production is a common technique used to enhance the perceived acoustic properties of multimedia content. Traditionally, Foley sound has been produced by human Foley artists, which involves manual recording and mixing of sound. However, recent advances in sound synthesis and generative models have generated interest in machine-assisted or… Continue reading Foley sound synthesis at the DCASE 2023 challenge