


L’intelligence artificielle est partout, y compris dans le domaine musical. Qu’il s’agisse de “générer” des musiques à partir de données existantes, de créer une musique 100 % originale ou de réaliser certaines tâches pratiques, les usages sont nombreux et les inquiétudes aussi.
Category: Media
Loïc demonstrates his FTM Synthesizer on Erae Touch

A demonstration by independent researcher Loïc Jankowiak, who visited LS2N in 2023 and 2024 as part of the ApEx project of Han Han.
This is an in-progress build of a physically-modelled drum synthesizer using the Functional Transformation Method (FTM), with external MIDI control. The Embodme Erae Touch control surface is used for the velocity and impact position on the virtual drum’s surface, and the Behringer X-Touch Mini is used for controlling the various parameters of the physical model, i.e. the material properties.
Bibliothécaire musical : un métier en transition ?

L’Association pour la Coopération des professionnels de l’Information musicale (ACIM) organise son congrès 2024 à Orléans. Le thème ce cette année est : “Bibliothécaire musical : un métier en transition ?”.
8 février 2024 : “Les sens artificiels” au Stereolux

Le jeudi 8 février 2024 à 18h30 au Stereolux, dans le cadre de la Nuit blanche des chercheur-e-s de Nantes université.
L’intelligence artificielle (IA) révolutionne notre compréhension du vivant en utilisant les sens humains. Elle permet une analyse poussée de la parole, des signaux sonores et de la bioacoustique. En médecine, les sens peuvent être reproduits pour améliorer les diagnostics. Dans la nature, les sens peuvent être simulés pour améliorer la compréhension du vivant. Au cours de cette session animée par des expert·es renommé·es, explorez les avancées de l’IA pour la santé et le vivant du futur.
Mathieu, Vincent, and Modan present at DCASE

Our group has presented two challenge tasks and two papers at the international workshop on Detection and Classification of Acoustic Scenes and Events (DCASE), held in Tampere (Finland) in September 2023.
16 novembre 2023 : journée GdR ISIS “Traitement du signal pour la musique”
Dans le cadre de l’action « Traitement du signal pour l’audio et l’écoute artificielle » du GdR ISIS, nous organisons, le Jeudi 16 Novembre 2023 à l’IRCAM, une troisième journée dédiée au traitement des signaux de musique
Fitting Auditory Filterbanks with MuReNN @ IEEE WASPAA
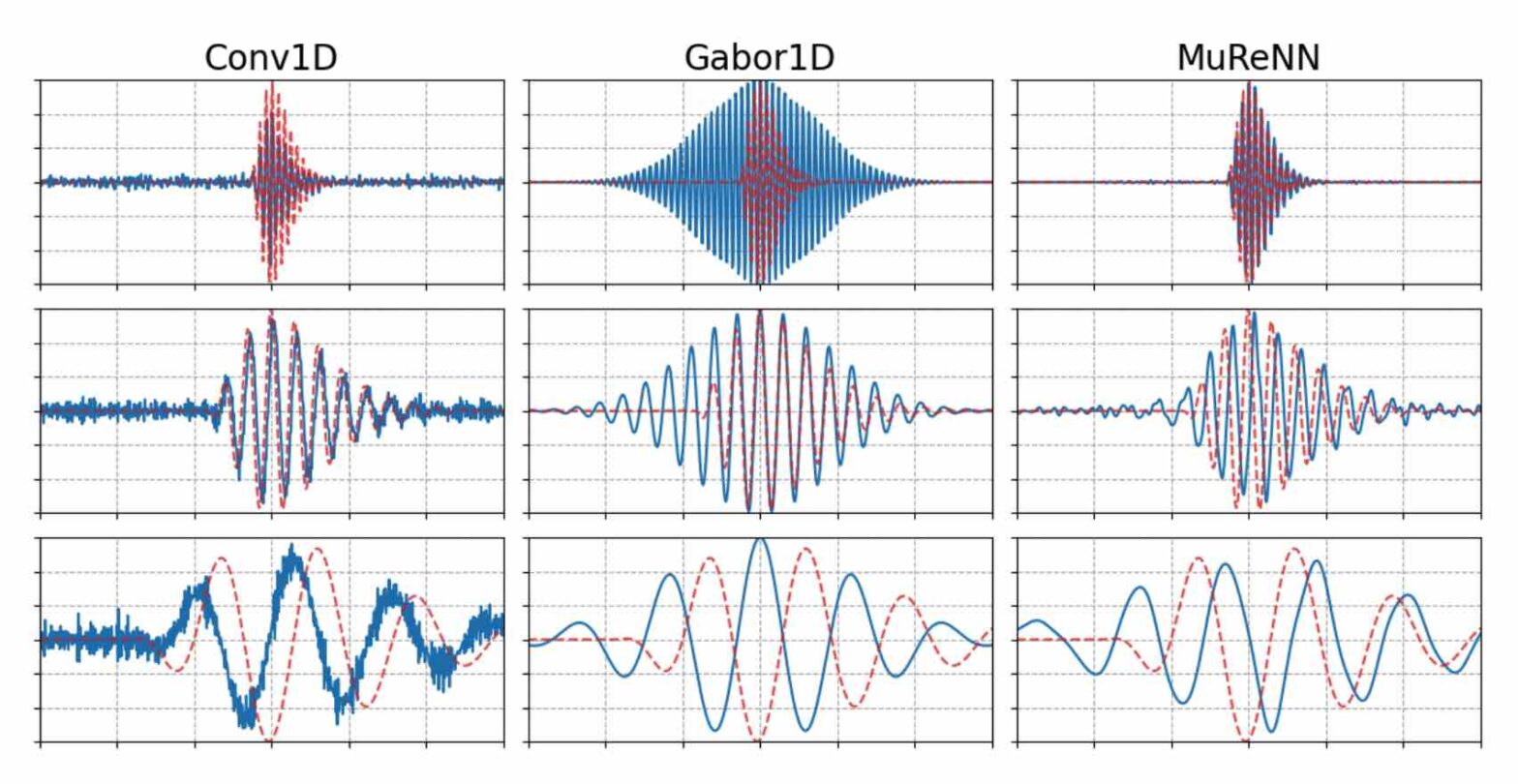
Waveform-based deep learning faces a dilemma between nonparametric and parametric approaches. On one hand, convolutional neural networks (convnets) may approximate any linear time-invariant system; yet, in practice, their frequency responses become more irregular as their receptive fields grow. On the other hand, a parametric model such as LEAF is guaranteed to yield Gabor filters, hence an optimal time-frequency localization; yet, this strong inductive bias comes at the detriment of representational capacity. In this paper, we aim to overcome this dilemma by introducing a neural audio model, named multiresolution neural network (MuReNN). The key idea behind MuReNN is to train separate convolutional operators over the octave subbands of a discrete wavelet transform (DWT). Since the scale of DWT atoms grows exponentially between octaves, the receptive fields of the subsequent learnable convolutions in MuReNN are dilated accordingly. For a given real-world dataset, we fit the magnitude response of MuReNN to that of a wellestablished auditory filterbank: Gammatone for speech, CQT for music, and third-octave for urban sounds, respectively. This is a form of knowledge distillation (KD), in which the filterbank “teacher” is engineered by domain knowledge while the neural network “student” is optimized from data. We compare MuReNN to the state of the art in terms of goodness of fit after KD on a hold-out set and in terms of Heisenberg time-frequency localization. Compared to convnets and Gabor convolutions, we find that MuReNN reaches state-of-the-art performance on all three optimization problems.
L’innovation peut-elle conduire à plus de sobriété dans la musique enregistrée ?

Une table ronde sur les enjeux écologiques de la musique enregistrée, organisée par le Centre national de la musique (CNM) à l’occasion des Rencontres de l’innovation dans la musique 2023. Cette table ronde coïncide avec la sortie du recueil “Musique et données”. Avec : Modération : Emily Gonneau – Causa