

Urban noise maps and noise visualizations traditionally provide macroscopic representations of noise levels across cities. However, those representations fail at accurately gauging the sound perception associated with these sound environments, as perception highly depends on the sound sources involved. This paper aims at analyzing the need for the representations of sound sources, by identifying the urban stakeholders for whom such representations are assumed to be of importance. Through spoken interviews with various urban stakeholders, we have gained insight into current practices, the strengths and weaknesses of existing tools and the relevance of incorporating sound sources into existing urban sound environment representations. Three distinct use of sound source representations emerged in this study: 1) noise-related complaints for industrials and specialized citizens, 2) soundscape quality assessment for citizens, and 3) guidance for urban planners. Findings also reveal diverse perspectives for the use of visualizations, which should use indicators adapted to the target audience, and enable data accessibility.
Author: Mathieu Lagrange
“Sensing the City Using Sound Sources: Outcomes of the CENSE Project” @ Urban Sound Symposium

Full program at: https://urban-sound-symposium.org/program/
Challenge on Sound Scene Synthesis: Evaluating Text-to-Audio Generation @ NeurIPS Audio Imagination workshop
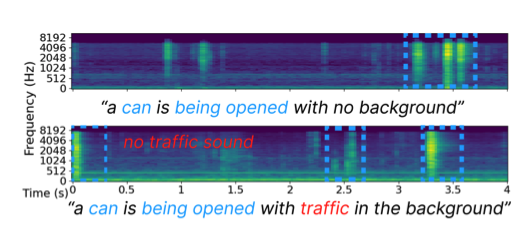
Despite significant advancements in neural text-to-audio generation, challenges persist in controllability and evaluation. This paper addresses these issues through the Sound Scene Synthesis challenge held as part of the Detection and Classification of Acoustic Scenes and Events 2024. We present an evaluation protocol combining objective metric, namely Fréchet Audio Distance, with perceptual assessments, utilizing a structured prompt format to enable diverse captions and effective evaluation. Our analysis reveals varying performance across sound categories and model architectures, with larger models generally excelling but innovative lightweight approaches also showing promise. The strong correlation between objective metrics and human ratings validates our evaluation approach. We discuss outcomes in terms of audio quality, controllability, and architectural considerations for text-to-audio synthesizers, providing direction for future research.
Detection of Deepfake Environmental Audio @ EUSIPCO
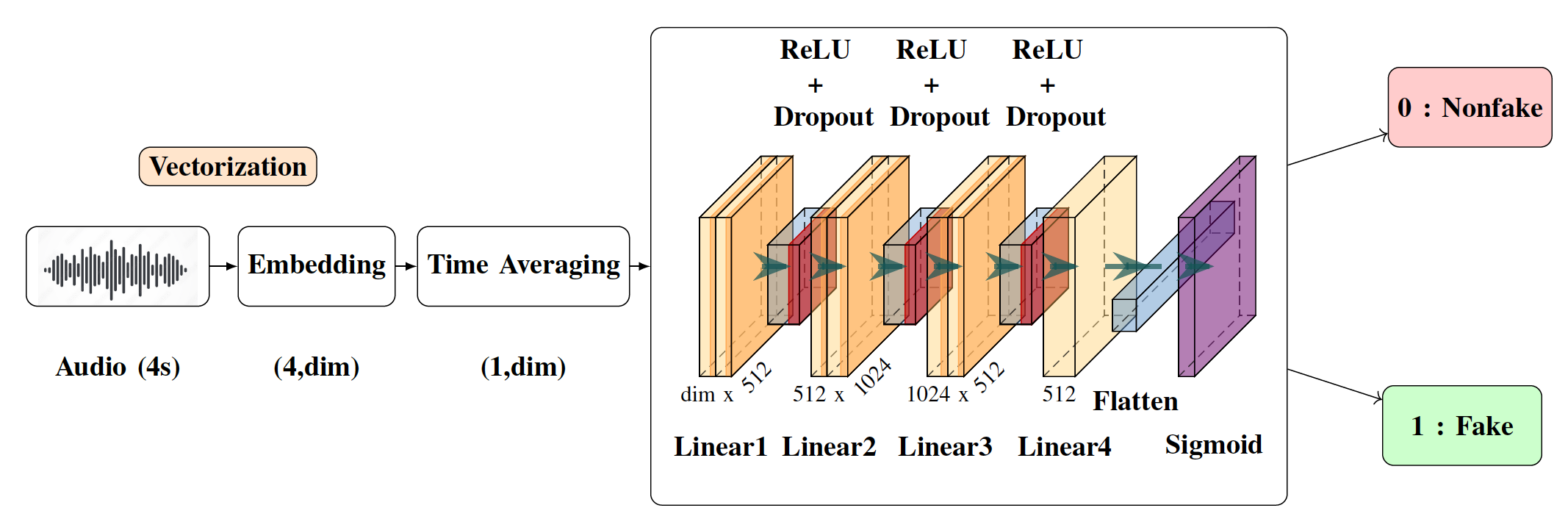
With the ever-rising quality of deep generative models,
it is increasingly important to be able to discern whether the
audio data at hand have been recorded or synthesized. Although
the detection of fake speech signals has been studied extensively,
this is not the case for the detection of fake environmental audio.
We propose a simple and efficient pipeline for detecting fake
environmental sounds based on the CLAP audio embedding. We
evaluate this detector using audio data from the 2023 DCASE
challenge task on Foley sound synthesis.
Our experiments show that fake sounds generated by 44 stateof-
the-art synthesizers can be detected on average with 98% accuracy.
We show that using an audio embedding trained specifically
on environmental audio is beneficial over a standard VGGish
one as it provides a 10% increase in detection performance. The
sounds misclassified by the detector were tested in an experiment
on human listeners who showed modest accuracy with nonfake
sounds, suggesting there may be unexploited audible features.
Sound source classification for soundscape analysis using fast third-octave bands data from an urban acoustic sensor network @ JASA
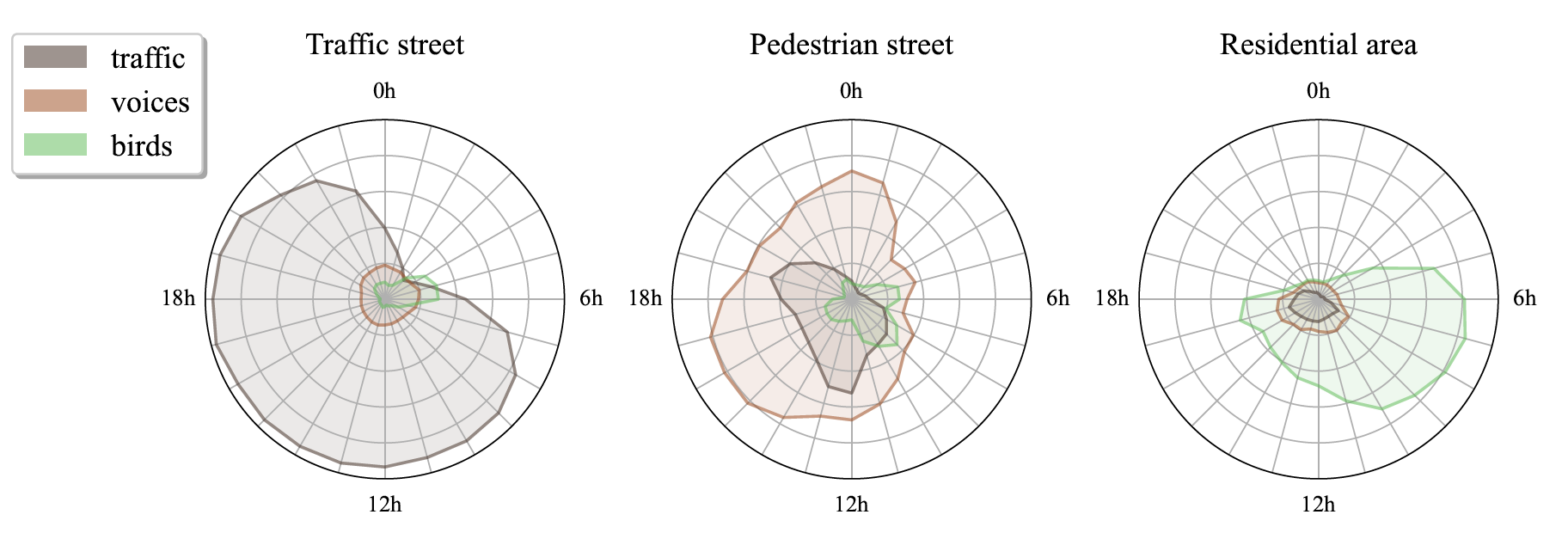
The exploration of the soundscape relies strongly on the characterization of the sound sources in the sound environment. Novel sound source classifiers, called pre-trained audio neural networks (PANNs), are capable of predicting the presence of more than 500 diverse sound sources. Nevertheless, PANNs models use fine Mel spectro-temporal representations as input, whereas sensors of an urban noise monitoring network often record fast third-octaves data, which have significantly lower spectro-temporal resolution. In a previous study, we developed a transcoder to transform fast third-octaves into the fine Mel spectro-temporal representation used as input of PANNs. In this paper, we demonstrate that employing PANNs with fast third-octaves data, processed through this transcoder, does not strongly degrade the classifier’s performance in predicting the perceived time of presence of sound sources. Through a qualitative analysis of a large-scale fast third-octave dataset, we also illustrate the potential of this tool in opening new perspectives and applications for monitoring the soundscapes of cities.
EMVD dataset: a dataset of extreme vocal distortion techniques used in heavy metal @ CBMI
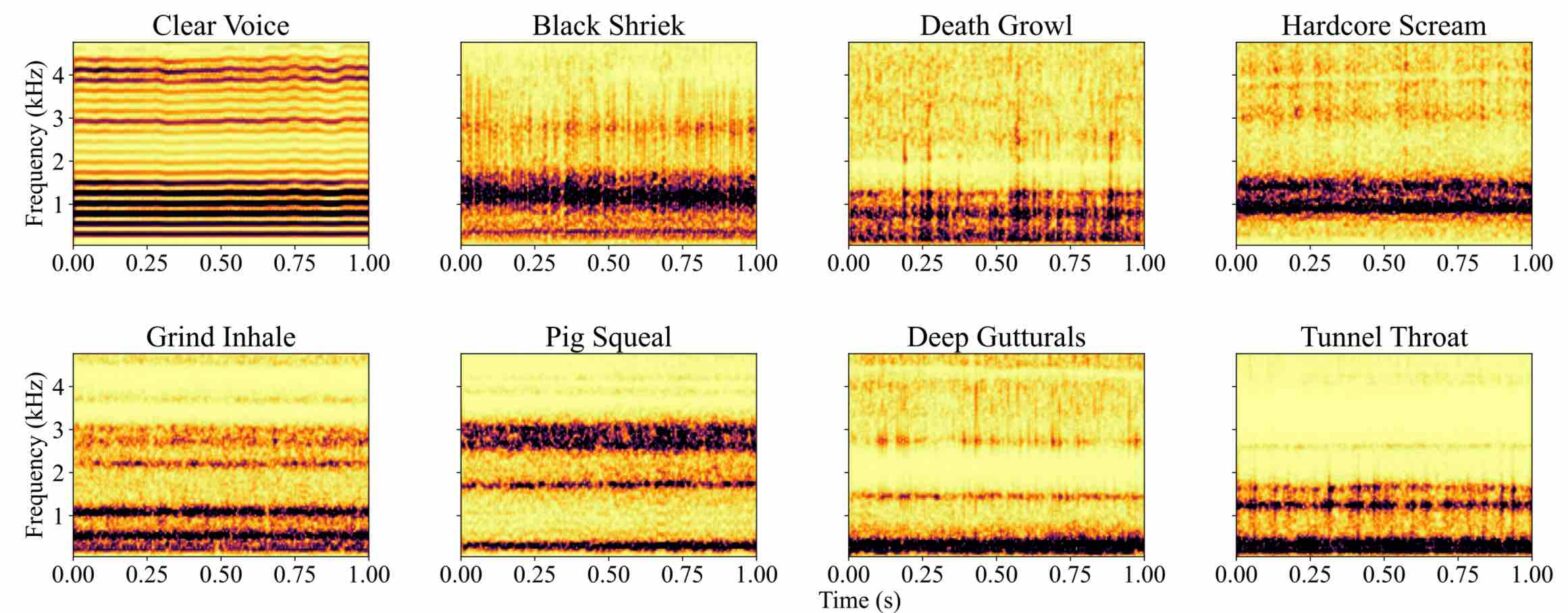
In this paper, we introduce the Extreme Metal Vocals Dataset, which comprises a collection of recordings of extreme vocal techniques performed within the realm of heavy metal music. The dataset consists of 760 audio excerpts of 1 second to 30 seconds long, totaling about 100 min of audio material, roughly composed of 60 minutes of distorted voices and 40 minutes of clear voice recordings. These vocal recordings are from 27 different singers and are provided without accompanying musical instruments or post-processing effects. The distortion taxonomy within this dataset encompasses four distinct distortion techniques and three vocal effects, all performed in different pitch ranges. Performance of a state-of-the-art deep learning model is evaluated for two different classification tasks related to vocal techniques, demonstrating the potential of this resource for the audio processing community.
Correlation of Fréchet Audio Distance With Human Perception of Environmental Audio Is Embedding Dependent @ EUSIPCO
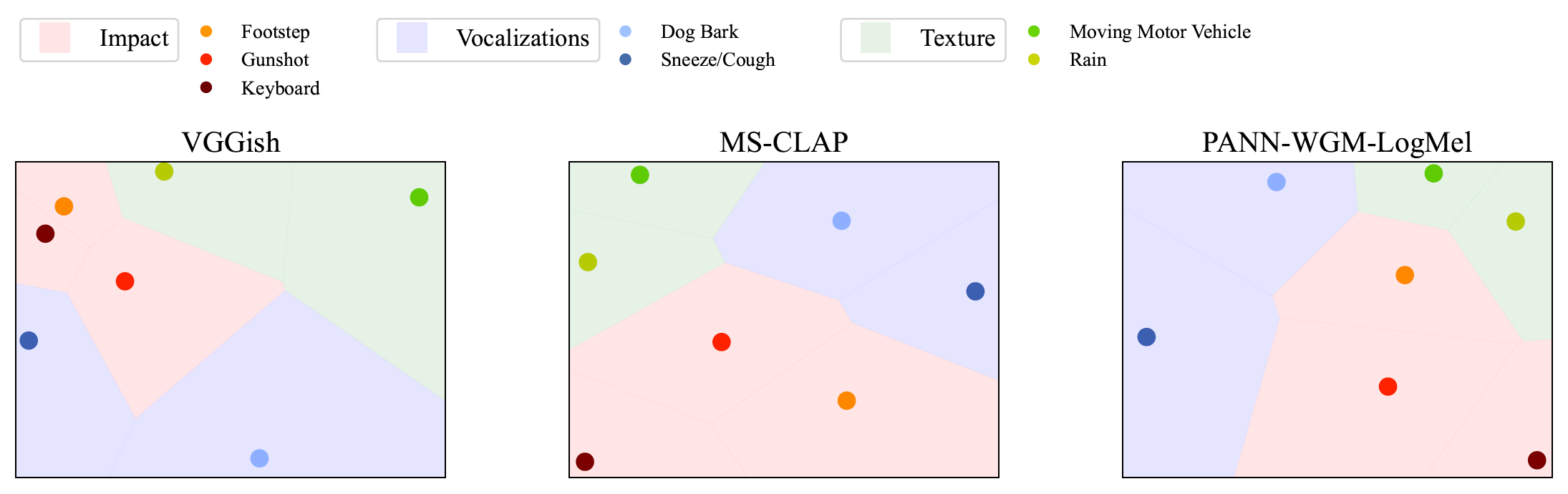
This paper explores whether considering alternative domain-specific embeddings to calculate the Frechet Audio Dis- tance (FAD) metric can help the FAD to correlate better with perceptual ratings of environmental sounds. We used embeddings from VGGish, PANNs, MS-CLAP, L-CLAP, and MERT, which are tailored for either music or environmental sound evaluation. The FAD scores were calculated for sounds from the DCASE 2023 Task 7 dataset. Using perceptual data from the same task, we find that PANNs-WGM-LogMel produces the best correlation between FAD scores and perceptual ratings of both audio quality and perceived fit with a Spearman correlation higher than 0.5. We also find that music-specific embeddings resulted in significantly lower results. Interestingly, VGGish, the embedding used for the original Frechet calculation, yielded a correlation below 0.1. These results underscore the critical importance of the choice of embedding for the FAD metric design.
On the Robustness of Musical Timbre Perception Models: From Perceptual to Learned Approaches @ EUSIPCO
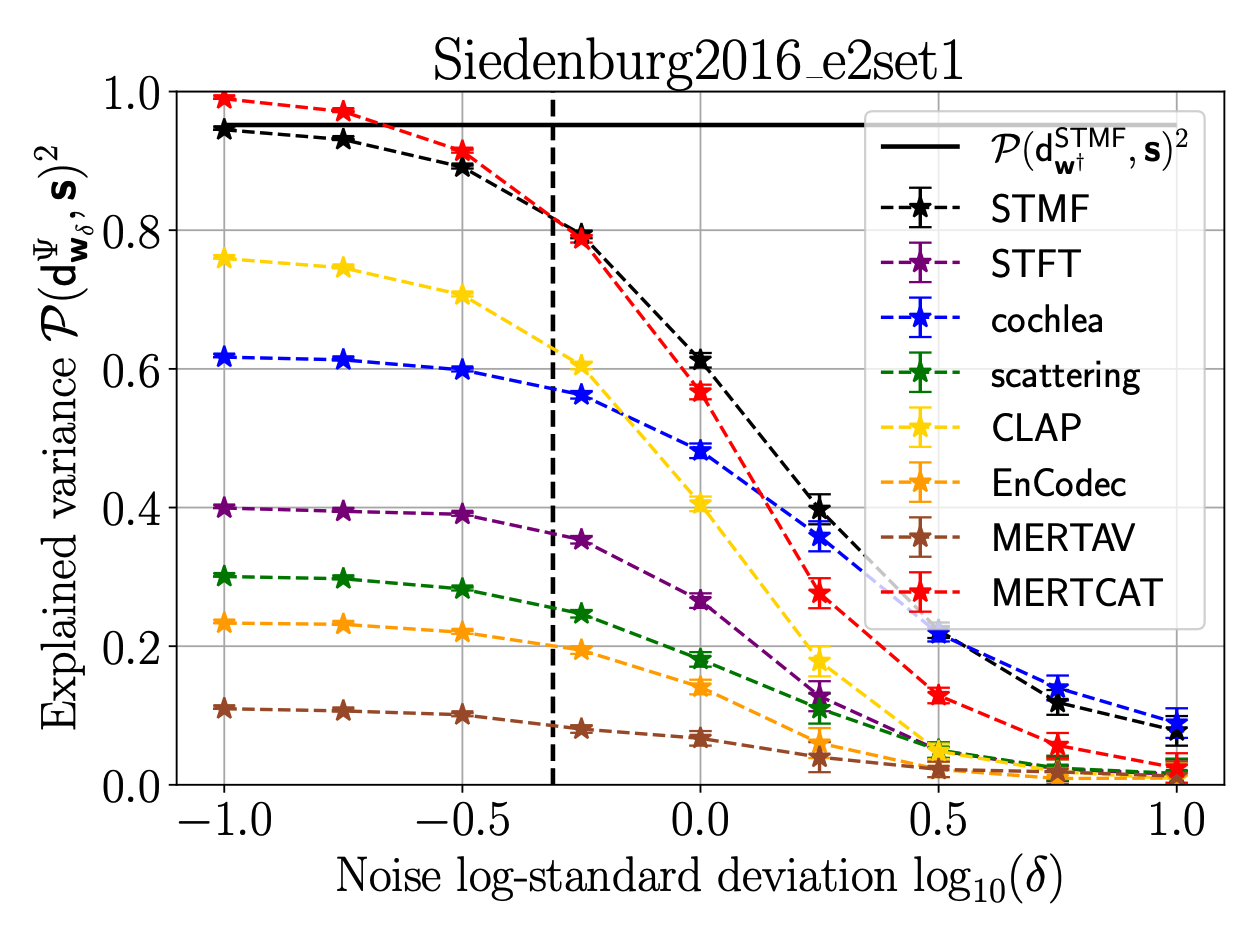
Timbre, encompassing an intricate set of acoustic cues, is key to identify sound sources, and especially to discriminate musical instruments and playing styles. Psychoacoustic studies focusing on timbre deploy massive efforts to explain human timbre perception. To uncover the acoustic substrates of timbre perceived dissimilarity, a recent work leveraged metric learning strategies on different perceptual representations and performed a meta-analysis of seventeen dissimilarity rated musical audio datasets. By learning salient patterns in very high-dimensional representations, metric learning accounts for a reasonably large part of the variance in human ratings. The present work shows that combining the most recent deep audio embeddings with a metric learning approach makes it possible to explain almost all the variance in human dissimilarity ratings. Furthermore, the robustness of the learning procedure against simulated human rating variability is thoroughly investigated. Intensive numerical experiments support the explanatory power and robustness against degraded dissimilarity ratings of the learning metric strategy using deep embeddings.
Content-Based Indexing for Audio and Music: From Analysis to Synthesis

Audio has long been a key component of multimedia research. As far as indexing is concerned, the research and industrial context has changed drastically in the last 20 years or so. Today, applications of audio indexing range from karaoke applications to singing voice synthesis and creative audio design. This special session aims at bringing together researchers that aim at proposing new tools or paradigms to investigate audio and music processing in the context of indexation and corpus-based generation.
Learning to Solve Inverse Problems for Perceptual Sound Matching @ IEEE TASLP
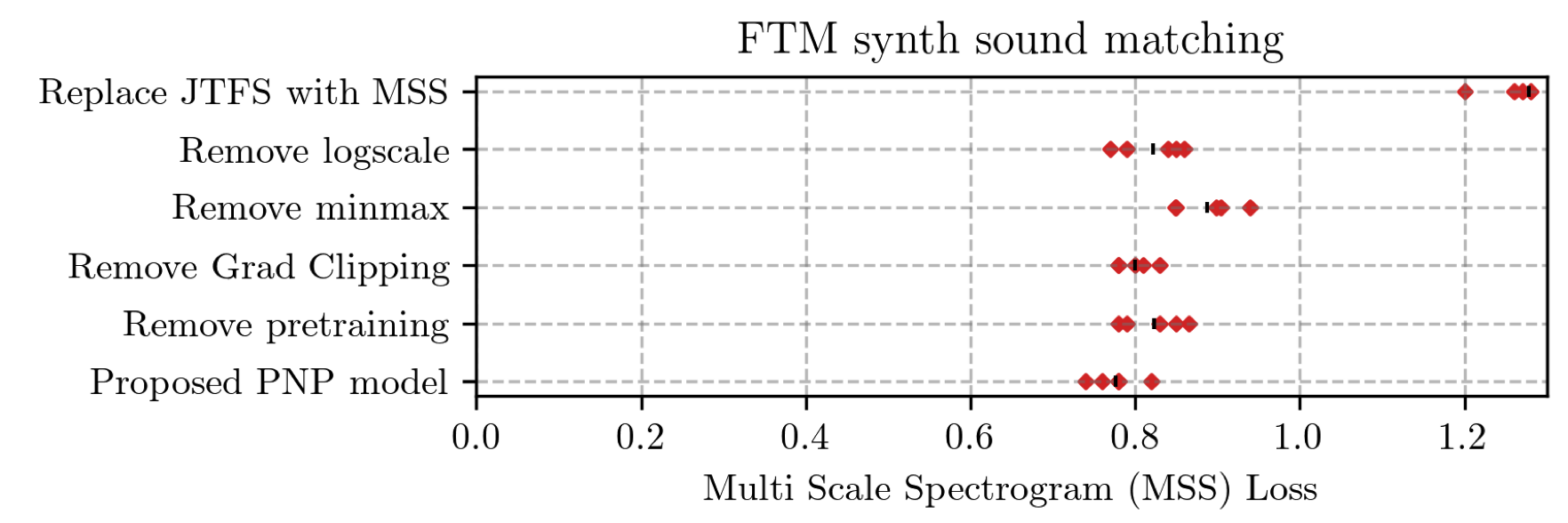
Perceptual sound matching (PSM) aims to find the input parameters to a synthesizer so as to best imitate an audio target. Deep learning for PSM optimizes a neural network to analyze and reconstruct prerecorded samples. In this context, our article addresses the problem of designing a suitable loss function when the training set is generated by a differentiable synthesizer. Our main contribution is perceptual–neural–physical loss (PNP), which aims at addressing a tradeoff between perceptual relevance and computational efficiency. The key idea behind PNP is to linearize the effect of synthesis parameters upon auditory features in the vicinity of each training sample. The linearization procedure is massively parallelizable, can be precomputed, and offers a 100-fold speedup during gradient descent compared to differentiable digital signal processing (DDSP). We show that PNP is able to accelerate DDSP with joint time–frequency scattering transform (JTFS) as auditory feature while preserving its perceptual fidelity. Additionally, we evaluate the impact of other design choices in PSM: parameter rescaling, pretraining, auditory representation, and gradient clipping. We report state-of-the-art results on both datasets and find that PNP-accelerated JTFS has greater influence on PSM performance than any other design choice.