


“STONE: Self-supervised tonality estimator”, at École Centrale de Nantes, amphi E, 2pm.
Tag: s4ml-project
STONE: Self-supervised tonality estimator @ ISMIR
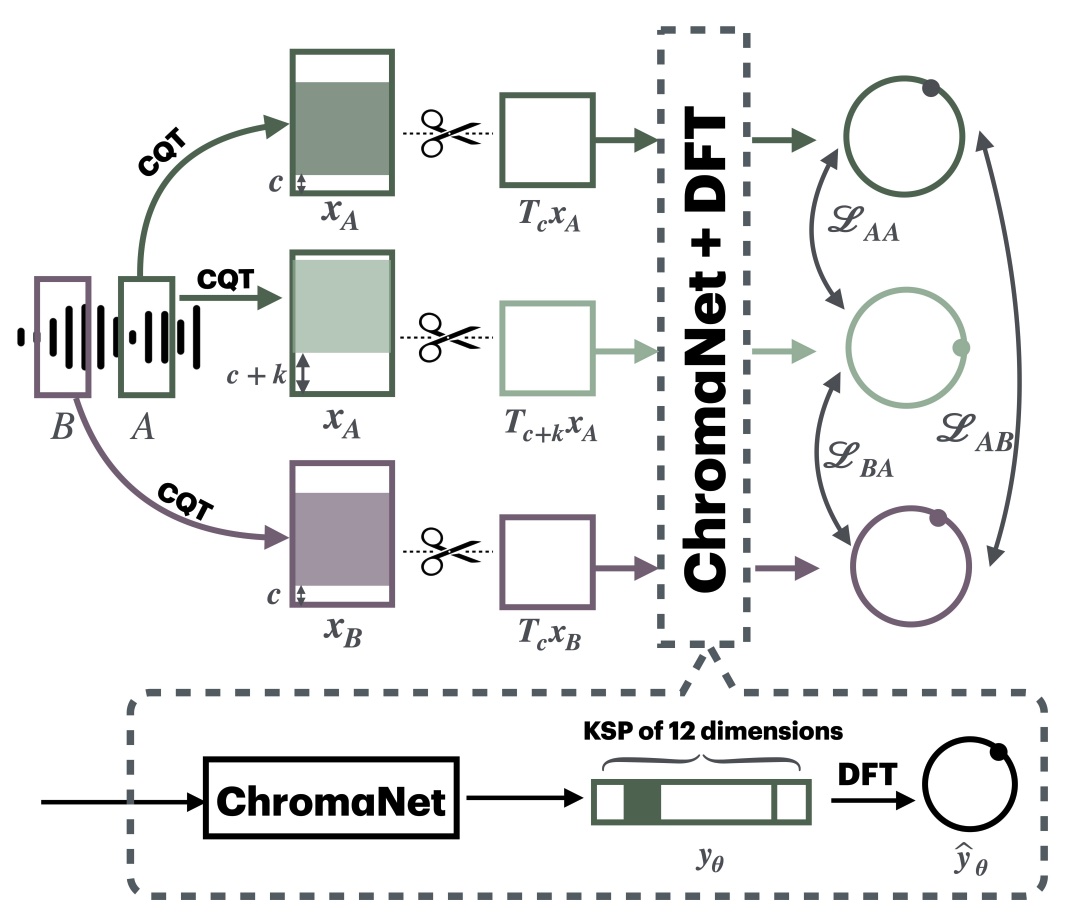
Although deep neural networks can estimate the key of a musical piece, their supervision incurs a massive annotation effort. Against this shortcoming, we present STONE, the first self-supervised tonality estimator. The architecture behind STONE, named ChromaNet, is a convnet with octave equivalence which outputs a “key signature profile” (KSP) of 12 structured logits. First, we train ChromaNet to regress artificial pitch transpositions between any two unlabeled musical excerpts from the same audio track, as measured as cross-power spectral density (CPSD) within the circle of fifths (CoF). We observe that this self-supervised pretext task leads KSP to correlate with tonal key signature. Based on this observation, we extend STONE to output a structured KSP of 24 logits, and introduce supervision so as to disambiguate major versus minor keys sharing the same key signature. Applying different amounts of supervision yields semi-supervised and fully supervised tonality estimators: i.e., Semi-TONEs and Sup-TONEs. We evaluate these estimators on FMAK, a new dataset of 5489 real-world musical recordings with expert annotation of 24 major and minor keys. We find that Semi-TONE matches the classification accuracy of Sup-TONE with reduced supervision and outperforms it with equal supervision.
Zero-Note Samba: Self-supervised beat tracking @ IEEE TASLP
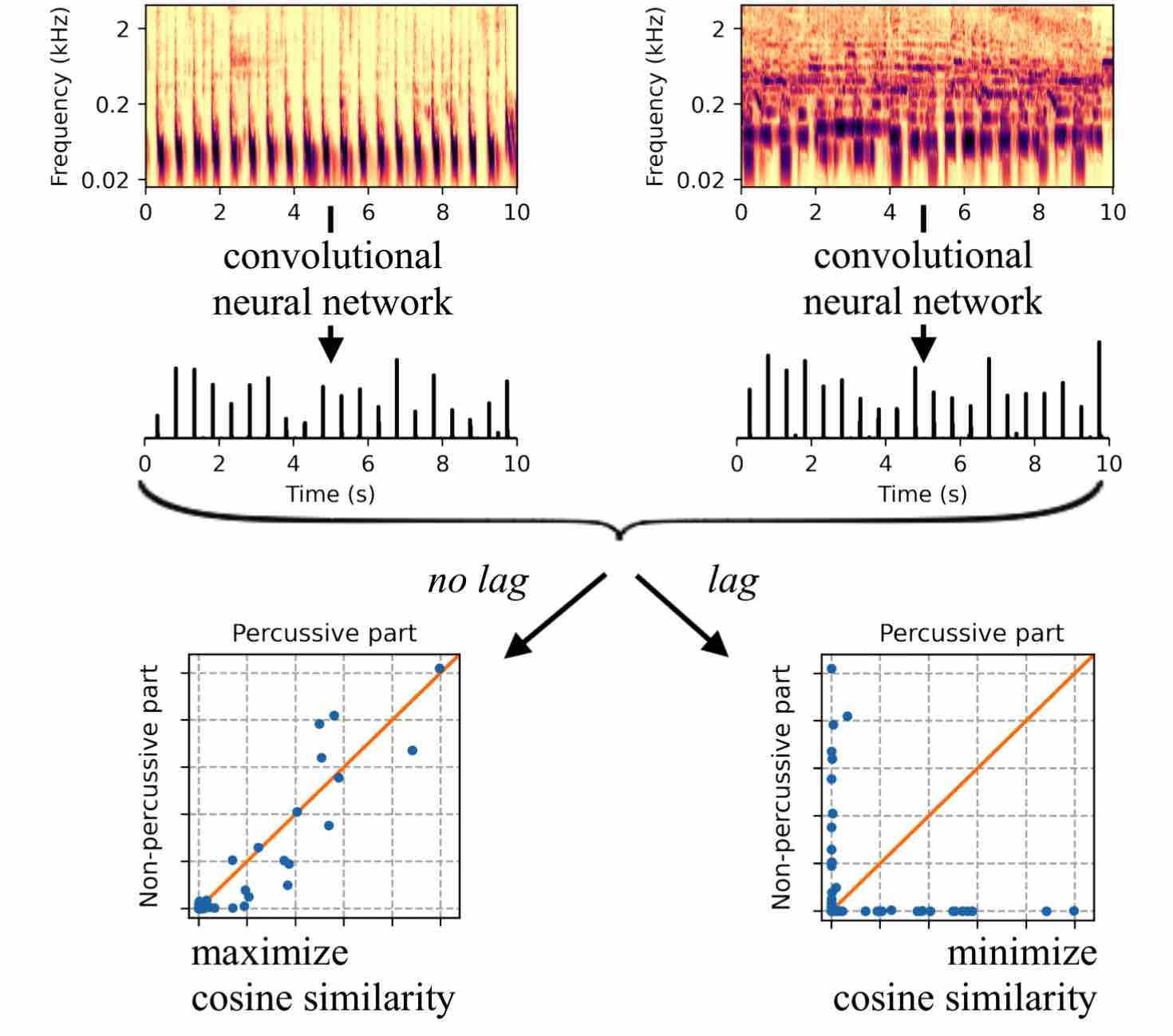
Supervised machine learning for music information retrieval requires a large annotated training set, and thus a high cognitive workload. To circumvent this problem, we propose to train deep neural networks to perceive beats in musical recordings despite having little or no access to human annotations. The key idea, which we name “Zero-Note Samba” (ZeroNS), is to train two fully convolutional networks in parallel: the first analyzes the percussive part of a musical piece whilst the second analyzes its non-percussive part. These networks learn a self-supervised pretext task of synchrony prediction (sync-pred), which simulates the ability of musicians to groove together when playing in the same band. Sync-pred encourages the two networks to return similar outputs if the underlying musical parts are synchronized, yet dissimilar outputs if the parts are out of sync. In practice, we obtain the instrumental parts from commercial recordings via an off-the-shelf source separation system: Spleeter. After self-supervised learning with sync-pred, ZeroNS produces a sparse output that resembles a beat detection function. When used in conjunction with a dynamic Bayesian network, ZeroNS surpasses the state of the art in unsupervised beat tracking. Furthermore, fine-tuning ZeroNS to a small set of labeled data (of the order of one to ten songs) matches the performance of a fully supervised network on 96 songs. Lastly, we show that pre-training a supervised model with sync-pred mitigates dataset bias and thus improves cross-dataset generalization, at no extra annotation cost.