

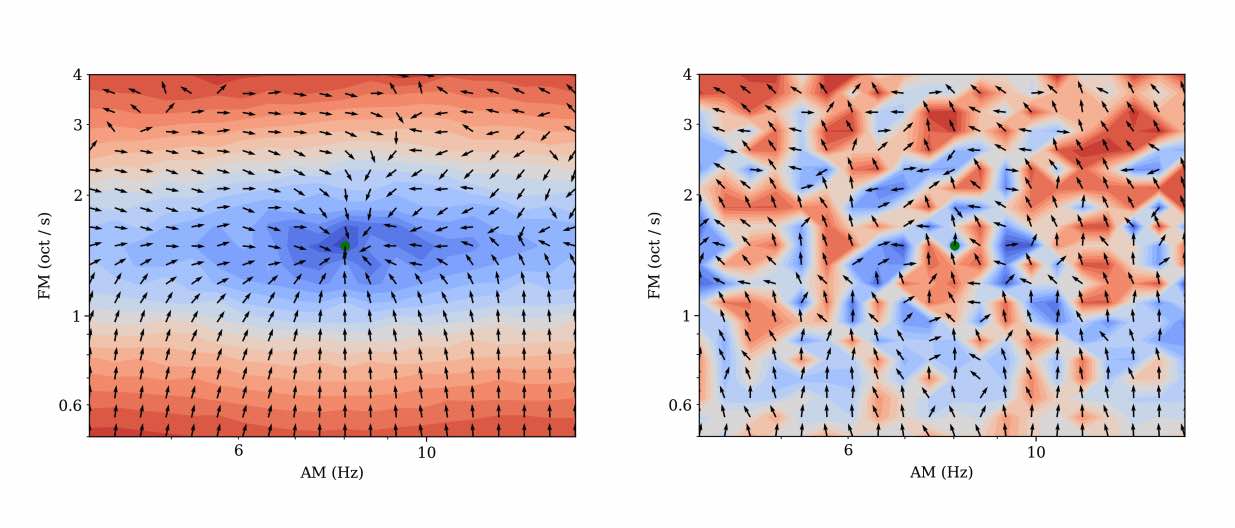
Mesostructures: Beyond Spectrogram Loss in Differentiable Time-Frequency Analysis
Articles dans une revue
Auteurs : Cyrus Vahidi, Han Han, Changhong Wang, Mathieu Lagrange, György Fazekas, Vincent Lostanlen.
Publié dans : Journal of the Audio Engineering Society
Date de publication : 2023