

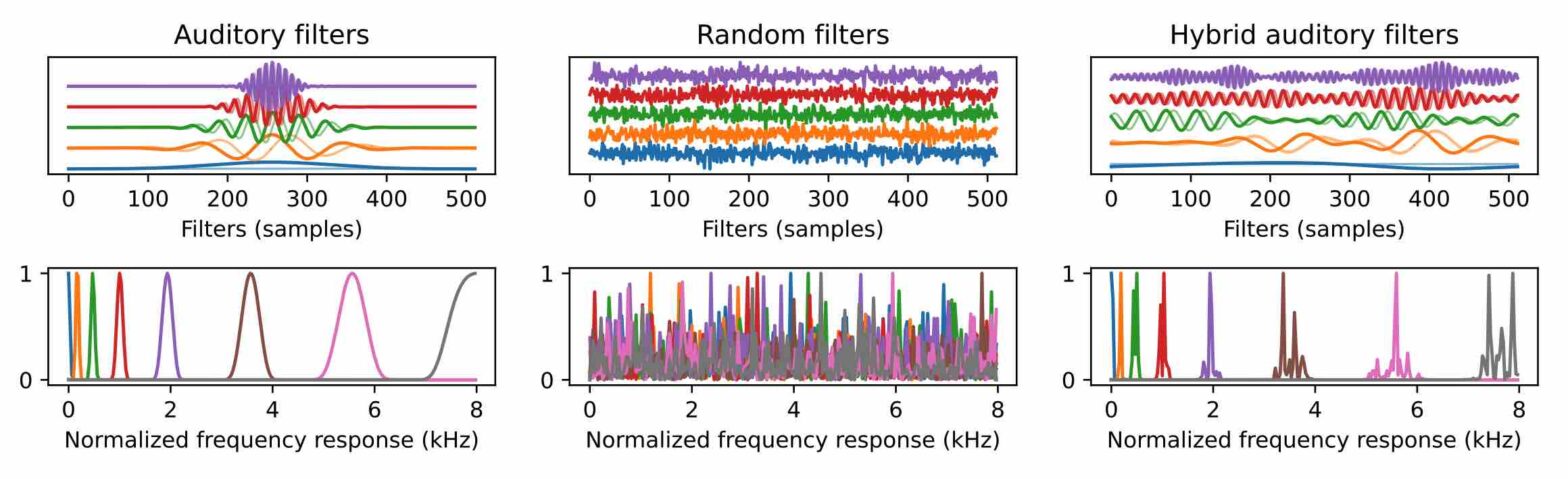
Hold Me Tight : Stable Encoder-Decoder Design for Speech Enhancement
Communications dans un congrès
Auteurs : Daniel Haider, Felix Perfler, Vincent Lostanlen, Martin Ehler, Peter Balazs.
Conférence : INTERSPEECH
Date de publication : 2024
Hybrid filterbanksStabilizationTight framesEncoderReconstructionSpeech enhancement