


UPCOMING EVENTS

“Sensing the City Using Sound Sources: Outcomes of the CENSE Project” @ Urban Sound Symposium
The city is arguably a very complex system to monitor and describe. The deployment of acoustic sensor networks can lead to new ways of doing so, potentially at scale. From the data produced by those networks, identifying sound sources is an emerging method of interest to provide meaningful information to the citizens. During this talk, I will discuss the outcomes of the deployment of such a network in the city of Lorient (France) that operated from 2020 to 2021, including notably the French COVID lockdown period.

Postdoc offer: “Deep learning and multiresolution analysis for audio”
We are looking to recruit a postdoc as part of the ANR project on multi-resolution neural networks (MuReNN). The goal is to work towards more efficient and interpretable models for deep learning in audio.
.")
OTHER NEWS
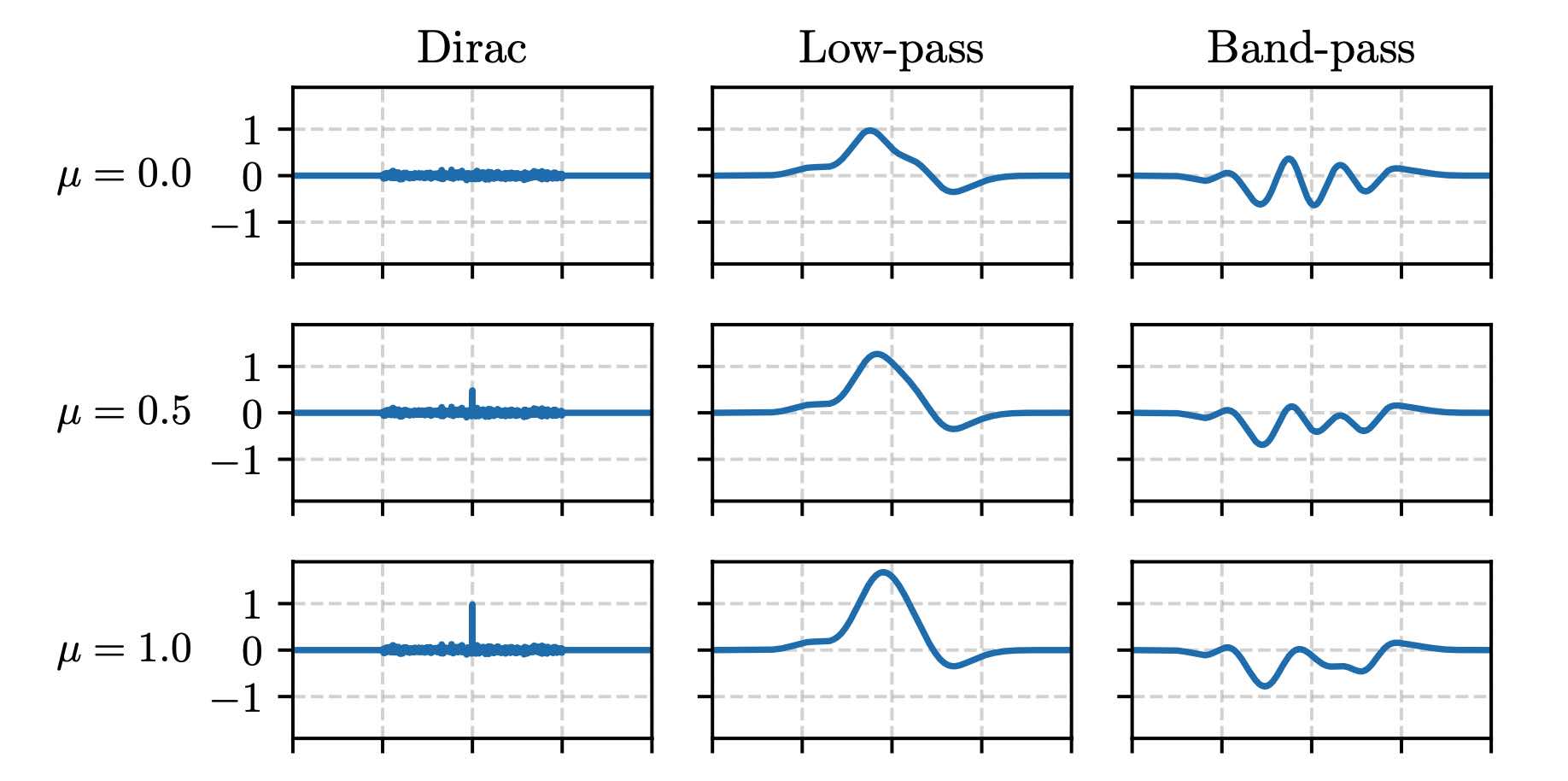
Residual Hybrid Filterbanks @ IEEE SSP
A hybrid filterbanks is a convolutional neural network (convnet) whose learnable filters operate over the subbands of a non-learnable filterbank, which is designed from domain knowledge. While hybrid filterbanks have found successful applications in speech enhancement, our paper shows that they remain susceptible to large deviations of the energy response due to randomness of convnet weights at initialization. Against this issue, we propose a variant of hybrid filterbanks, by inspiration from residual neural networks (ResNets). The key idea is to introduce a shortcut connection at the output of each non-learnable filter, bypassing the convnet. We prove that the shortcut connection in a residual hybrid filterbank lowers the relative standard deviation of the energy response while the pairwise cosine distances between non-learnable filters contributes to preventing duplicate features.

Podcast “L’éco-acoustique” sur Le Labo des Savoirs
Et si écouter littéralement la nature nous renseignait sur l’état de notre biodiversité ? Un podcast de Sophie Podevin avec Jérôme Sueur, Flore Samaran et Vincent Lostanlen.

Robust Deconvolution with Parseval Filterbanks @ IEEE SampTA
This article introduces two contributions: Multiband Robust Deconvolution (Multi-RDCP), a regularization approach for deconvolution in the presence of noise; and Subband-Normalized Adaptive Kernel Evaluation (SNAKE), a first-order iterative algorithm designed to efficiently solve the resulting optimization problem. Multi-RDCP resembles Group LASSO in that it promotes sparsity across the subband spectrum of the solution. We prove that SNAKE enjoys fast convergence rates and numerical simulations illustrate the efficiency of SNAKE for deconvolving noisy oscillatory signals.

Le streaming comme infrastructure et comme mode de vie @ RNRM
L’enquête sur l’impact écologique du streaming musical révèle deux angles d’analyse : l’un fondé sur l’infrastructure matérielle, l’autre sur l’évolution des modes de vie. À l’heure où les architectures de choix sont de plus en plus verrouillées autour d’un petit nombre de géants du numérique, l’enjeu de cette enquête réside dans une complémentarité entre méthodes quantitatives et méthodes qualitatives, ainsi que dans une interdisciplinarité entre sciences du numérique, sciences humaines et sociales et sciences du système Terre. Dans ce contexte, critiquer l’insoutenabilité du streaming ne signifie pas s’en remettre à une innovation technologique qui pourrait soudain « verdir » la filière dans son ensemble. Bien plutôt, il s’agit de dénoncer et contester l’utopie d’une musique intégralement disponible, pour tout le monde, partout, tout de suite. Pour se rendre crédibles, les scénarios alternatifs au statu quo doivent définir, dans un même geste technocritique, quel mode de vie ils promeuvent et quelle infrastructure ils maintiendront.
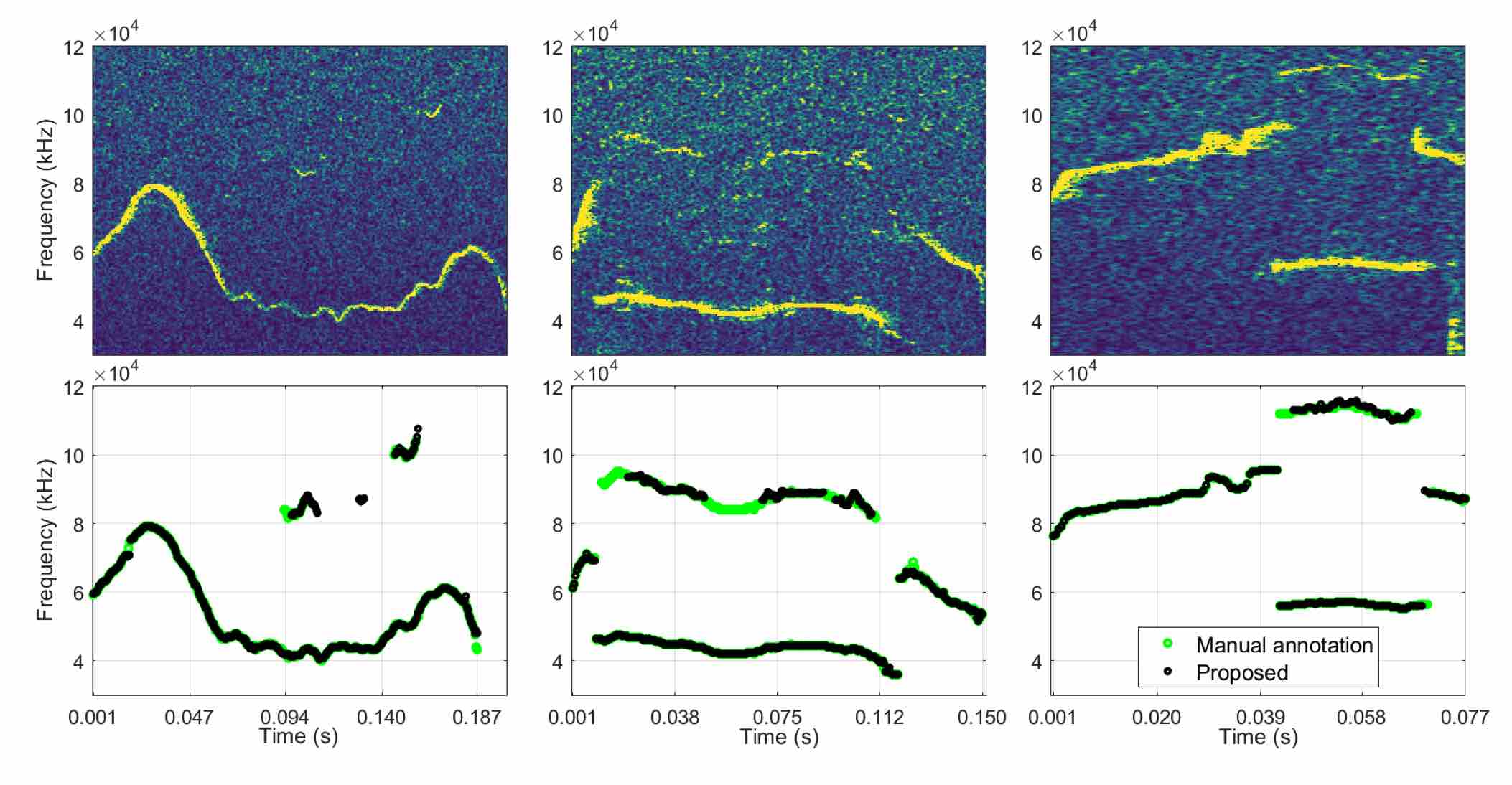
Robust Multicomponent Tracking of Ultrasonic Vocalizations @ IEEE ICASSP
Ultrasonic vocalizations (USV) convey information about individual identity and arousal status in mice. We propose to track USV as ridges in the time-frequency domain via a variant of timefrequency reassignment (TFR). The key idea is to perform TFR with empirical Wiener shrinkage and multitapering to improve robustness to noise. Furthermore, we perform TFR over both the short-term Fourier transform and the constant-Q transform so as to detect both the fundamental frequency and its harmonic partial (if any). Experimental results show that our approach effectively estimates multicomponent ridges with high precision and low frequency deviation.

S-KEY: Self-Supervised Learning of Major and Minor Keys from Audio @ IEEE ICASSP
STONE, the current method in self-supervised learning for tonality estimation in music signals, cannot distinguish relative keys, such as C major versus A minor. In this article, we extend the neural network architecture and learning objective of STONE to perform self-supervised learning of major and minor keys (S-KEY). Our main contribution is an auxiliary pretext task to STONE, formulated using transposition-invariant chroma features as a source of pseudo-labels. S-KEY matches the supervised state of the art in tonality estimation on FMAKv2 and GTZAN datasets while requiring no human annotation and having the same parameter budget as STONE. We build upon this result and expand the training set of S-KEY to a million songs, thus showing the potential of large-scale self-supervised learning in music information retrieval.

Introducing: Clara Boukhemia
Clara is working on augmented reality approaches to improve sound comfort in indoor environments, specifically in shared workspaces. She is a PhD student, supervised by Nicolas Misdariis from the Ircam in Paris and Mathieu Lagrange from the SIMS team at LS2N.
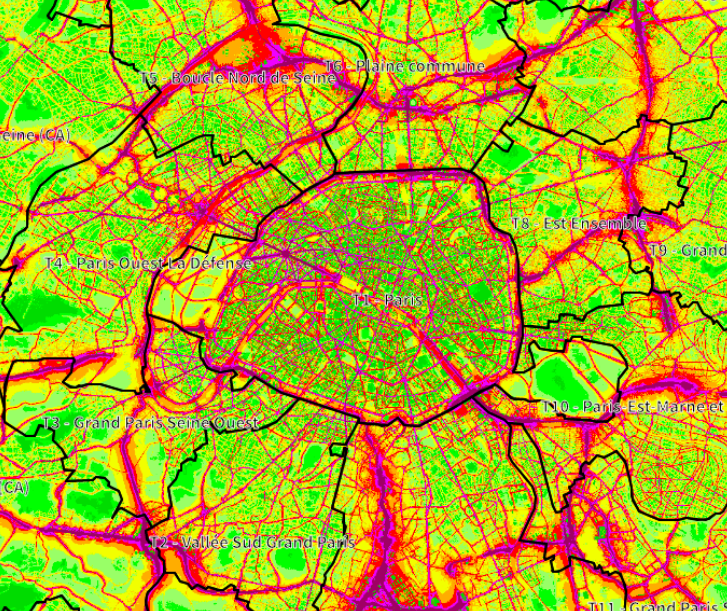
Towards better visualizations of urban sound environments: insights from interviews @ Inter-Noise
Urban noise maps and noise visualizations traditionally provide macroscopic representations of noise levels across cities. However, those representations fail at accurately gauging the sound perception associated with these sound environments, as perception highly depends on the sound sources involved. This paper aims at analyzing the need for the representations of sound sources, by identifying the urban stakeholders for whom such representations are assumed to be of importance. Through spoken interviews with various urban stakeholders, we have gained insight into current practices, the strengths and weaknesses of existing tools and the relevance of incorporating sound sources into existing urban sound environment representations. Three distinct use of sound source representations emerged in this study: 1) noise-related complaints for industrials and specialized citizens, 2) soundscape quality assessment for citizens, and 3) guidance for urban planners. Findings also reveal diverse perspectives for the use of visualizations, which should use indicators adapted to the target audience, and enable data accessibility.
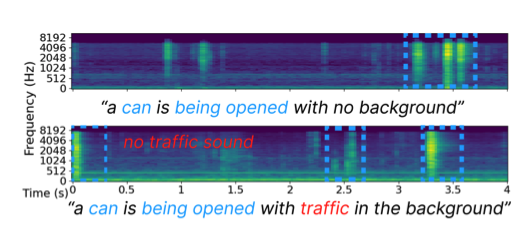
Challenge on Sound Scene Synthesis: Evaluating Text-to-Audio Generation @ NeurIPS Audio Imagination workshop
Despite significant advancements in neural text-to-audio generation, challenges persist in controllability and evaluation. This paper addresses these issues through the Sound Scene Synthesis challenge held as part of the Detection and Classification of Acoustic Scenes and Events 2024. We present an evaluation protocol combining objective metric, namely Fréchet Audio Distance, with perceptual assessments, utilizing a structured prompt format to enable diverse captions and effective evaluation. Our analysis reveals varying performance across sound categories and model architectures, with larger models generally excelling but innovative lightweight approaches also showing promise. The strong correlation between objective metrics and human ratings validates our evaluation approach. We discuss outcomes in terms of audio quality, controllability, and architectural considerations for text-to-audio synthesizers, providing direction for future research.

Podcast “Musique et IA” sur France musique
L’intelligence artificielle est partout, y compris dans le domaine musical. Qu’il s’agisse de “générer” des musiques à partir de données existantes, de créer une musique 100 % originale ou de réaliser certaines tâches pratiques, les usages sont nombreux et les inquiétudes aussi.

Model-based deep learning for music information research @ IEEE Signal Processing Magazine
We refer to the term model-based deep learning for approaches that combine traditional knowledge-based methods with data-driven techniques, especially those based on deep learning, within a differentiable computing framework. In music, prior knowledge for instance related to sound production, music perception or music composition theory can be incorporated into the design of neural networks and associated loss functions. We outline three specific scenarios to illustrate the application of model-based deep learning in MIR, demonstrating the implementation of such concepts and their potential.

BirdVox in MIT Technology Review
Vincent speaks to MIT Technology Review on the past, present, and future of machine learning for bird migration monitoring.

Introducing: Reyhaneh Abbasi
Reyhaneh is working on the generation of mouse ultrasonic vocalizations, with applications to animal behavior research.

Introducing: Matthieu Carreau
Matthieu is working on audio signal processing algorithms that can run on autonomous sensors subject to intermitent power supply. He is a PhD student, advised by Vincent Lostanlen, Pierre-Emmanuel Hladik, and Sébastien Faucou.
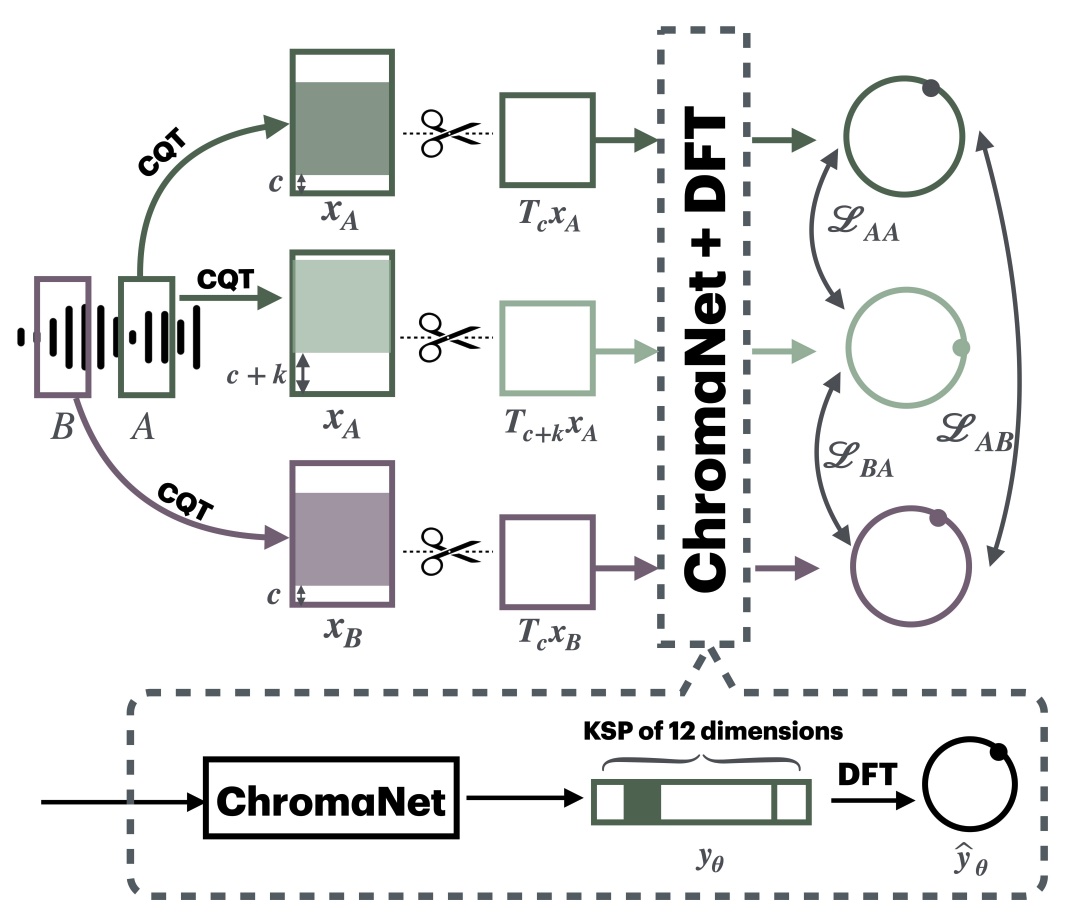
STONE: Self-supervised tonality estimator @ ISMIR
Although deep neural networks can estimate the key of a musical piece, their supervision incurs a massive annotation effort. Against this shortcoming, we present STONE, the first self-supervised tonality estimator. The architecture behind STONE, named ChromaNet, is a convnet with octave equivalence which outputs a “key signature profile” (KSP) of 12 structured logits. First, we train ChromaNet to regress artificial pitch transpositions between any two unlabeled musical excerpts from the same audio track, as measured as cross-power spectral density (CPSD) within the circle of fifths (CoF). We observe that this self-supervised pretext task leads KSP to correlate with tonal key signature. Based on this observation, we extend STONE to output a structured KSP of 24 logits, and introduce supervision so as to disambiguate major versus minor keys sharing the same key signature. Applying different amounts of supervision yields semi-supervised and fully supervised tonality estimators: i.e., Semi-TONEs and Sup-TONEs. We evaluate these estimators on FMAK, a new dataset of 5489 real-world musical recordings with expert annotation of 24 major and minor keys. We find that Semi-TONE matches the classification accuracy of Sup-TONE with reduced supervision and outperforms it with equal supervision.